- SQL Server – Introdução ao estudo de Performance Tuning
- Entendendo o funcionamento dos índices no SQL Server
- SQL Server – Como identificar uma query lenta ou “pesada” no seu banco de dados
- SQL Server – Dicas de Performance Tuning: Conversão implícita? NUNCA MAIS!
- SQL Server – Comparação de performance entre Scalar Function e CLR Scalar Function
- SQL Server – Dicas de Performance Tuning: Qual a diferença entre Seek Predicate e Predicate?
- SQL Server – Utilizando colunas calculadas (ou colunas computadas) para Performance Tuning
- SQL Server – Como identificar e coletar informações de consultas demoradas utilizando Extended Events (XE)
- SQL Server – Como identificar todos os índices ausentes (Missing indexes) de um banco de dados
- SQL Server e Azure SQL Database: Como Identificar ocorrências de Key Lookup através da plancache
Olá pessoal,
Tudo bem ?
Neste post eu gostaria de começar a falar sobre um assunto que eu gosto bastante, que é Performance Tuning, assunto no qual já palestrei no 2º Encontro do Chapter SQL Server ES – 10/06/2017.
Esse tema está sempre entre os mais procurados por profissionais de banco de dados, desenvolvedores e empresas que buscam consultorias de DBA experientes. Diferente de muitas áreas do banco de dados, Performance Tuning exige sempre uma análise do problema e diversos testes antes de qualquer ação. Apesar de existirem boas práticas para isso, não existe uma fórmula mágica ou “receita de bolo” que sempre irá resolver os problemas de performance, independente do cenário e ambiente.
Espero que vocês gostem dessa série 🙂
Por quê Performance Tuning é tão importante?
- “No mundo atual, a maioria das pessoas não tem paciência para esperar um site carregar por muito tempo e acabam entrando em outro logo em seguida.” (escoladomarketingdigital.com.br)
- “Em média, usuários deixam qualquer site se ele não carregar no celular dentro de três segundos” (Google)
- Um dos maiores motivos para o fracasso do Windows Vista foi o fato de ser um sistema extremamente pesado e lento (tecnoblog.net)
- “O tablet TouchPad, da HP, foi um dos lançamentos mais esperados de 2011 – e logo se converteu no maior fracasso do ano. O aparelho, criado para concorrer com o iPad, da Apple, durou apenas sete semanas no mercado antes de a HP tomar a decisão de acabar com ele, citando como motivo as vendas fracas. O motivo? Os consumidores reconheceram imediatamente que o celular era lento demais” (estadao.com.br)
- “55% dos estudantes do Canadá admitem se estressarem por computadores lentos, na síndrome da ampulheta (Hourglass Syndrome).” (nytimes.com)
- “66% dos americanos são estressados por computadores lentos e 23% se descrevem como muito estressados por conta disso.” (reuters.com)
No cenário de hoje em dia, os usuários não tem mais paciência de ficar esperando uma tela carregar ou o retorno de um clique no botão. Os usuários querem respostas rápidas nos sistemas e para isso, o banco de dados deve dar condições para os sistemas conseguirem consultar os dados no banco sem gerar esperas no sistema.
Para isso, o DBA precisa ter conhecimento para identificar possíveis lentidões, que podem ser causadas por diversos fatores:
- Ausência de índices na tabela ou índices ineficientes para uma determinada consulta
- Fragmentação dos índices ou tabela
- Locks
- Eventos de wait (Ex: PAGEIOLATCH_EX, OLEDB, etc)
- Consulta mal escrita
- CPU sobrecarregado
- Tempo de leitura do disco alto
- Volume de informações muito grande
- Contenção de tempdb
- Problemas de rede
Como é o trabalho de Performance Tuning?
Para se realizar uma análise de performance tuning, vou listar as atividades que geralmente são necessárias para atingir o seu objetivo:
Entender o problema
Essa atividade do processo de performance tuning consiste em identificar de forma macro, a origem da lentidão no ambiente. Caso você já saiba qual a rotina que vai tentar otimizar, esse processo já está concluído.
Nesta atividade, você deve consultar as rotinas e coletas de dados da sua instância para analisar, por exemplo:
- Rotinas com duração de tempo alto
- Rotinas que possuem um tempo de CPU alto
- Rotinas com volume de I/O alto (reads/writes)
- Análise de logs do servidor
- Análise dos eventos de wait da instância
- Análise de histórico de blocks e deadlocks
- Análise de histórico de rotinas em execução no momento da lentidão
- Análise de histórico de blocks e deadlocks
- Relatórios de fragmentação de índices e tabelas
- Relatórios de tabelas sem atualização de estatísticas
- Relatórios de missing index
Para que seja possível entender e identificar o problema, é necessário que você tenha todos (ou boa parte) dos controles indicados acima. Eles vão te fornecer dados e informações sobre o que acontece na sua instância quando um problema de performance ocorre.
Elaborar o diagnóstico
Agora que você já identificou o que está causando a lentidão, agora é hora de descobrir o porque ela está ocorrendo. Nesta etapa, iremos olhar de forma micro a rotina específica que está apresentando uma performance ruim, a fim de destrinchá-la e descobrir as consultas que podem ser otimizadas.
Nesta atividade, temos várias formas de ajudar na análise, como por exemplo:
- Análise do plano de execução, para identificar como a consulta está sendo feita internamente (e identificar possíveis anomalias, como conversão implícita)
- Análise dos índices utilizados, para garantir que eles estão cobrindo as consultas mais pesadas (covering index)
- Uso de SET STATISTICS IO e TIME, para medir a quantidade de leituras/escritas que são realizadas para cada objeto consultado, bem como o tempo de resposta de cada operação
- Em muitos casos, a estrutura do banco está otimizada, mas a query está mal escrita. Sendo assim, a consulta pode sofrer alterações para otimizar o uso dos índices já existentes
- Analisar os histograma do índice, para validar se ele está realmente sendo eficaz e fazendo sentido
Aplicar dicas e técnicas de otimização
Uma vez que você já identificou as consultas que estão apresentando baixa performance, chegou o momento de aplicar as técnicas de performance tuning, seja alteração da query (query tuning), criação/alteração dos índices, atualização de estatística, etc.
Nesta etapa, você provavelmente precisará testar mais de uma melhoria para atingir o melhor resultado, dependendo de como está o seu ambiente. Em muitos casos, você precisará de mais uma alteração para que a query seja otimizada.
Testes, Testes, Testes e depois, mais Testes!
Essa etapa, junto com a etapa de Aplicar dicas e técnicas de otimização, provavelmente são as que mais vão necessitar do seu tempo. Todo trabalho de performance tuning exige que as alterações sejam testadas e validadas antes de aplicadas no ambiente.
Como eu comentei anteriormente, não existe uma “receita de bolo” que será sempre mais performático em todas as situações (embora existam boas práticas que GERALMENTE, apresentam uma performance melhor). Já vi vários casos em que uma alteração deu um grande ganho de performance em um ambiente, e no outro acabou não fazendo efeito. Lembre-se: Existem N fatores que podem influenciar na performance do seu banco e todos devem ser considerados.
Pela minha experiência, eu te recomendo: JAMAIS aplique uma melhoria de performance sem testar BASTANTE antes de aplicar. Isso é especialmente recomendado se você fez alterações na consulta para atingir um desempenho melhor. No meu dia a dia, eu faço alterações em consultas tanto na parte estrutural quanto de regra de negócio, então o teste acaba sendo mais importante ainda.
Aplicar a otimização
Na etapa final do processo de Performance Tuning, que geralmente é a mais tranquila, você irá aplicar as alterações sugeridas no seu ambiente após uma intensa bateria de testes já realizados.
Se você tem mais de um ambiente na sua empresa (Ex: DEV, HOM, PRD), é muito interessante subir a alteração por ambiente, de forma a observar o comportamento do sistema após as mudanças.
Uma parte extremamente importante nesta etapa, é a coleta dos resultados obtidos após a aplicação das alterações. Essa parte do projeto de Performance Tuning é vital para ganhar a confiança no trabalho do DBA e conseguir mostrar as vantagens obtidas no dia a dia ao investir tempo (e consequentemente, dinheiro) nesse trabalho dentro da empresa.
Performance Tuning – Índices
Os índices no banco de dados são uma das estruturas mais importantes (talvez, a mais) no que se refere à performance de consultas. Índices são estruturas em disco associada a uma tabela ou view, que agilizam a recuperação das linhas ordenando os dados em forma de árvores binárias.
Fazendo uma analogia, ele seria como o índice ou sumário de um livro, fazendo com que você consiga buscar rapidamente o que está pesquisando. Embora os índices sejam extremamente úteis e eficazes, eles devem ser criados com muito rigor e critério: Índices ocupam espaço em disco, ou seja, se você cria muitos índices, eles podem ocupar mais espaço que a própria tabela.
Além disso, índices agilizam as consultas, mas deixam as operações de escritas mais lentas (INSERT, UPDATE, DELETE), porque essas operações precisam atualizar a tabela e os dados de todos os índices relacionados. Se você tem uma tabela que sobre muitas escritas e poucas leituras (Ex: Tabela de log/histórico), talvez essa tabela não seja uma boa candidata para a criação de índices. CUIDADO!
Alguns ótimos candidatos a fazerem parte de um índice são colunas computadas (calculadas) frequentemente acessadas, colunas que fazem parte de uma Foreign Key (FK), coluna identity da tabela.
Outro ótimo candidato para a criação de um índice pode ser identificado após uma análise mais profunda onde você identificou uma consulta muito pesada e que é realizada frequentemente no seu ambiente. Nesse caso, você irá criar um índice específico para essa consulta, que terá todas as colunas utilizadas por essa query, numa técnica conhecida como Covering Index.
Caso você queira se aprofundar mais sobre os índices no SQL Server, recomendo a leitura do post Entendendo o funcionamento dos índices no SQL Server.
Performance Tuning – O Plano de Execução
O Plano de execução é uma ferramenta gráfica para auxiliar do DBA/Desenvolvedor a entender como as consultas estão sendo realizadas no banco e interpretadas pelo otimizador de consultas. Essa ferramenta é de extrema importância para qualquer pessoa que pense em realizar uma trabalho de otimização de consulta no banco de dados, pois apenas entendendo como a consulta está sendo feita internamente que é possível identificar pontos de melhoria.

Exemplo de um plano de execução sendo analisado
O que podemos extrair de um plano?
- Está utilizando índice?
- Qual índice foi utilizado?
- Trabalho paralelizado?
- Qual o volume dos dados?
- Qual a operação de maior custo?
- Qual o operador que foi utilizado?
Como fazemos a leitura de um plano?
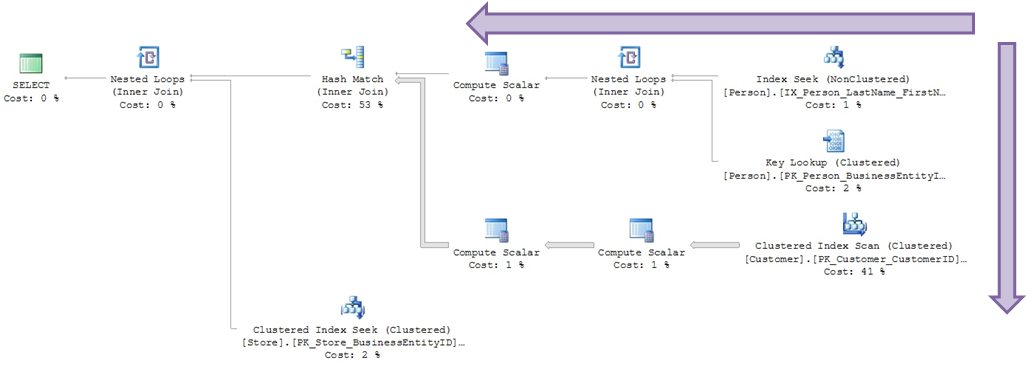
Setas indicam volume de registros processados:

Percentual do custo de cada operação

Informações detalhadas através de ToolTips
Sugestão de índices

Qual a diferença entre plano estimado e atual?
Plano estimado:
- Útil para desenvolvimento, onde não pode executar a consulta
- Muito útil em cenários onde a consulta original demora muito tempo para processar
- Não funciona com objetos temporários
- Não identifica alguns warnings (Ex: Residual I/O)
- Baseado nas estatísticas (se estiverem desatualizadas, podem distorcer a realidade)
Plano atual:
- A consulta original é executada no banco
- Ao final das operações, o plano de execução que foi realmente utilizado pelo otimizador de consulta é mostrado
Como visualizar o plano de execução da minha query?
Para conseguir visualizar o plano de execução da consulta que você vai executar, basta selecionar uma das 2 opções marcadas no print abaixo:
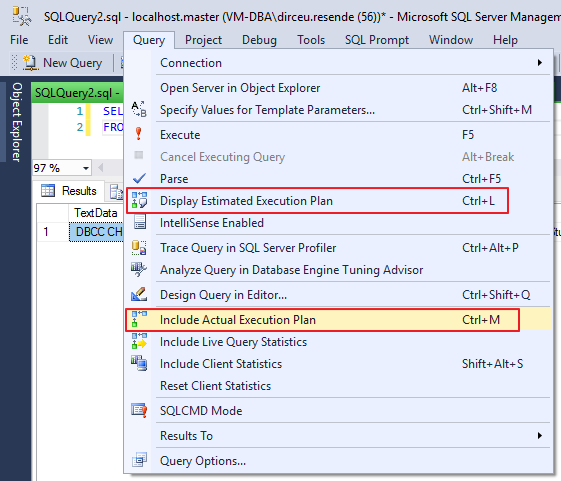
Opção na interface para exibir o plano de execução
Entretanto, elas possuem comportamentos diferentes: Ao selecionar a opção “Include Actual Execution Plan”, as consultas realizadas a partir desse momento irão retornar o plano gerado ao final da execução.
A opção “Display Estimated Execution Plan” deve ser utilizada ao selecionar as consultas em que você deseja visualizar o plano estimado.
Independente da forma escolhida, uma vez selecionada a opção, basta executar a sua consulta (Plano atual) ou visualizar o plano das consultas selecionadas (Plano estimado) para visualizar o plano de execução de forma gráfica no seu Management Studio (SSMS):
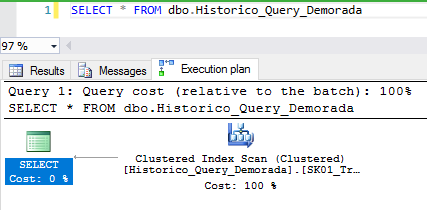
Uma outra forma de visualizar o plano de execução estimado, é através de comandos SET:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
SET SHOWPLAN_ALL OFF GO SET SHOWPLAN_XML ON GO SELECT * FROM dbo.Historico_Query_Demorada GO SET SHOWPLAN_XML OFF GO SET SHOWPLAN_ALL ON GO SELECT * FROM dbo.Historico_Query_Demorada |
Result:

Para visualizar graficamente o plano de execução, é só clicar no XML gerado:

Como visualizar o plano de execução de uma query em execução?
Para visualizar o plano de execução das consultas em execução, basta executar a query abaixo:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
SELECT A.session_id, B.command, A.login_name, C.query_plan FROM sys.dm_exec_sessions AS A WITH (NOLOCK) LEFT JOIN sys.dm_exec_requests AS B WITH (NOLOCK) ON A.session_id = B.session_id OUTER APPLY sys.dm_exec_query_plan(B.[plan_handle]) AS C WHERE A.session_id > 50 AND A.session_id <> @@SPID AND (A.[status] != 'sleeping' OR (A.[status] = 'sleeping' AND A.open_transaction_count > 0)) |
Se você quiser saber todas as informações das consultas em execução, inclusive com uso de CPU, tempdb, leituras, escritas, o próprio plano de execução da consulta e muito mais, dê uma olhada na versão simplificada da sp_whoisactive que disponibilizei no post SQL Server – Query para retornar as consultas em execução (sp_WhoIsActive sem consumir TempDB).
Como visualizar os planos de execução em cache?
Geralmente quando você executa uma consulta, o SQL Server vai gerar um plano de execução para ela e deixar esse plano guardado no cache do banco de dados, para o caso de que essa mesma query seja executada novamente, o otimizador de consulta não precise analisar a query e gerar um novo plano. Sendo assim, é possível visualizar os planos que estão gravados em cache no SQL Server.
Vale lembrar que toda vez que a instância é reiniciada os planos em cache são descartados. O SQL Server também mantém só os planos mais utilizados, pois ele não tem como armazenar os planos de cada consulta já realizada na instância.
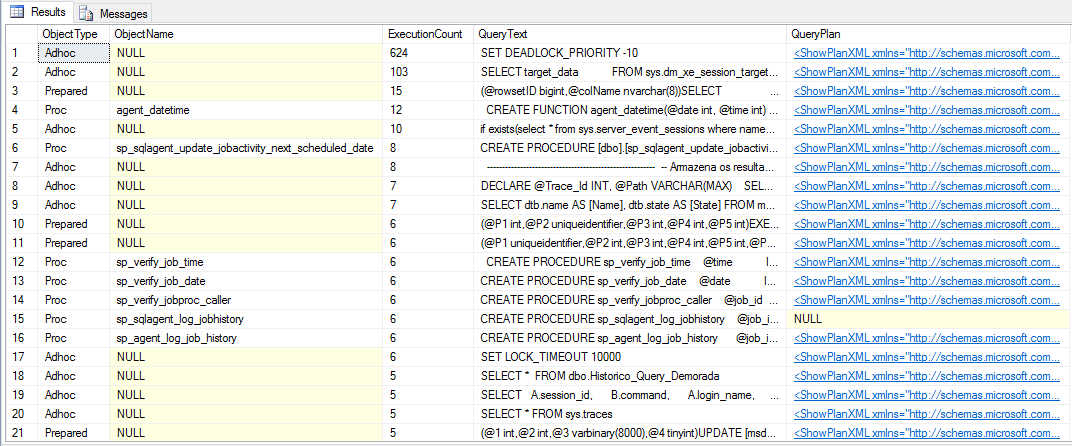
Para visualizar os planos em cache, basta utilizar a consulta abaixo:
|
1 2 3 4 5 6 7 8 9 10 11 12 |
SELECT cp.objtype AS ObjectType, OBJECT_NAME(st.objectid, st.dbid) AS ObjectName, cp.usecounts AS ExecutionCount, st.text AS QueryText, qp.query_plan AS QueryPlan FROM sys.dm_exec_cached_plans AS cp CROSS APPLY sys.dm_exec_query_plan(cp.plan_handle) AS qp CROSS APPLY sys.dm_exec_sql_text(cp.plan_handle) AS st ORDER BY ExecutionCount DESC |
Result:
Como apagar os planos de execução em cache?
Como mencionei acima, manter os planos de execução em cache é uma boa prática para evitar que o otimizador de consulta precise ficar analisando consultas e gerando novos planos de execução sem necessidade. Entretanto, em diversas situações é importante que você consiga apaga um determinado plano do cache ou até mesmo todos os planos.
Para apagar todo o cache da sua instância, basta executar o comando abaixo:
|
1 2 |
DBCC FREEPROCCACHE GO |
Para apagar todo o cache de um determinado database, execute este comando:
|
1 2 3 4 |
DECLARE @DbID INT = (SELECT database_id FROM sys.databases WHERE [name] = 'dirceuresende') DBCC FLUSHPROCINDB (@DbID) GO |
Para apagar o cache de uma stored procedure ou função, basta executar um comando de alter procedure/alter function que o plano é recriado.
Uma opção interessante é o hint WITH RECOMPILE, que ao ser utilizado na alteração de um objeto, faz com que um novo plano de execução seja criado a cada chamada desse objeto.
|
1 2 3 4 5 6 7 8 |
ALTER PROCEDURE [dbo].[stpTeste] WITH RECOMPILE -- A cada execução, será gerado um novo plano AS BEGIN SELECT 1 END |
Uma outra forma de forçar a recompilação de um objeto e gerar um novo plano de execução é utilizando a Stored Procedure interna sp_recompile:
|
1 |
sp_recompile @objname = 'dbo.stpBusca_Rastreamento_Correios' |

Quais são os principais operadores do Plano de Execução?
Nesta sessão, vou listar os operadores mais comuns e que você vai ver com mais frequência durante as suas análises.
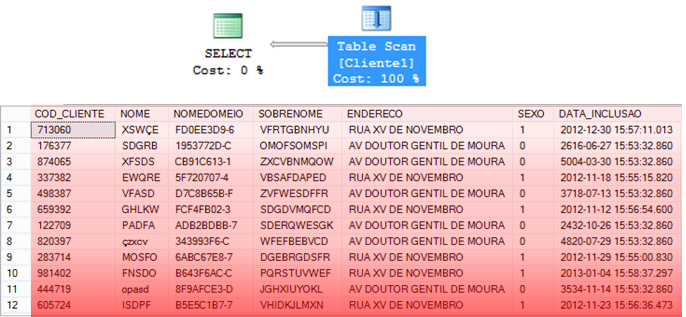
Table Scan
– Operador que consiste em ler TODOS os dados da tabela para encontrar as informações que devem ser retornadas.
– Acontece em tabela sem índice cluster
– Em geral, operação de alto custo
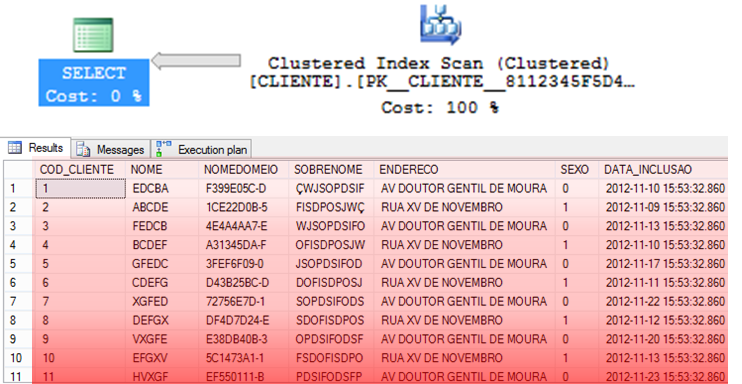
Clustered Index Scan
– Operador que consiste em ler TODOS os dados do índice CLUSTERED para encontrar as informações que devem ser retornadas.
– Em geral, costuma ser um pouco mais rápido que o Table Scan, pois os dados já estão ordenados no índice.
– Index Scan pode ser reflexo de um Lookup caro
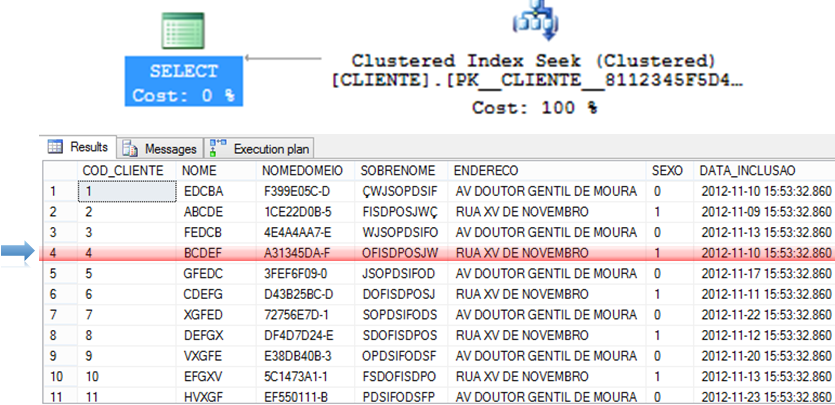
Clustered Index Seek e NonClustered Index Seek
– Algoritmo que costuma ser extremamente eficiente para retornar registros específicos.
– Como os dados já estão ordenados no índice, consegue utilizar algoritmos mais eficientes como QuickSort e ShellSort.
Key Lookup e RID Lookup
Quando é realizada uma consulta em uma tabela, o otimizador de consultas do SQL Server irá determinar qual o melhor método de acesso ao dados de acordo com as estatísticas coletada e escolher o que tiver o menor custo.
Como o índice clustered é a própria tabela, gerando um grande volume de dados, geralmente é utilizado o índice não clustered de menor custo para a consulta. Isso pode gerar um problema, pois muitas vezes a query está selecionando colunas onde nem todas estão indexadas, fazendo com que seja utilizado um índice não clustered para a busca das informações indexadas (Index Seek NonClustered) e também seja utilizado o índice clustered para retornar as informações restantes, onde o índice não cluster possui um ponteiro para a posição exata da informação no índice cluster (ou o ROWID, caso a tabela não tenha índice cluster).
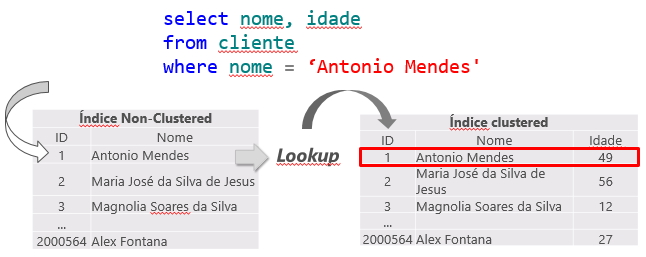
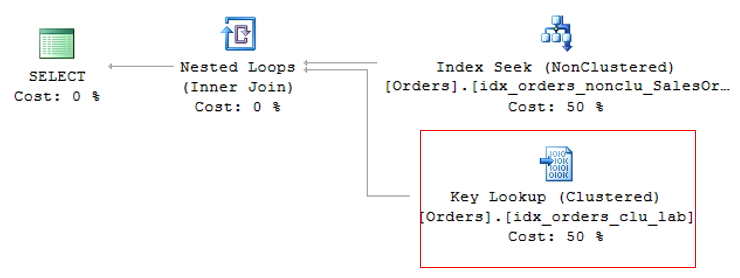
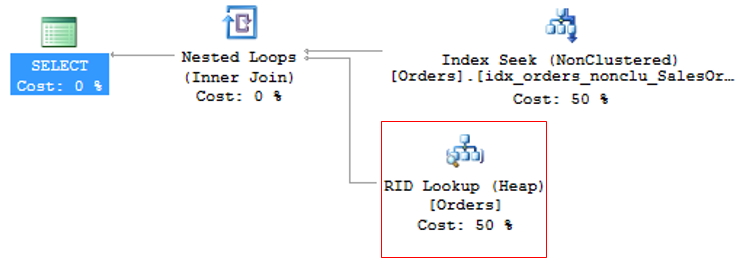
Essa operação é chamada de Key Lookup, no caso de tabelas com índice clustered ou RID Lookup (RID = Row ID) para tabelas que não possuem índice clustered (chamadas tabelas HEAP) e por gerar 2 operações de leituras para uma única consulta, deve ser evitada sempre que possível.
Key Lookup
RID Lookup
Para evitar o KeyLookup basta utilizar a técnica de cobrir o índice (Covering index), que consiste em adicionar ao índice NonClustered (INCLUDE) as principais colunas que são utilizadas nas consultas à tabela. Isso faz com que o otimizador de consulta consiga obter todas as informações lendo apenas o índice escolhido, sem precisar ler também o índice clustered.
Entretanto, deve-se tomar muita atenção na modelagem dos índices. Não é recomendável adicionar todas as colunas da tabela no índice não cluster, uma vez que ele ficará tão grande que ele não será mais efetivo e o otimizador de consulta poderá até mesmo decidir em não utilizá-lo e preferir o operador Index Scan, que faz a leitura sequencial de todo o índice, prejudicando a performance das consultas.
Para evitar o RID Lookup, basta criar o índice clustered na tabela e prestar atenção aos eventos de Key Lookup que possam vir a surgir.
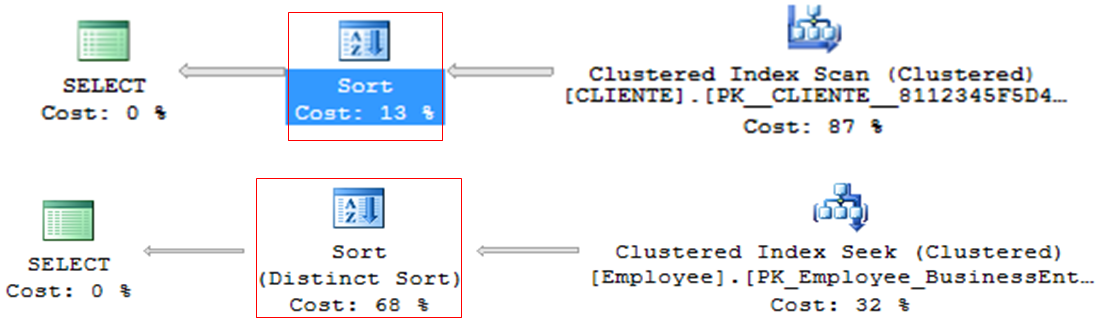
Sort
– Operador que costuma ser muito pesado nas consultas, especialmente com grandes volumas de dados
– Processamento linha a linha
– ORDER BY ou DISTINCT
– Geralmente, pode ser descartado e ordenado na aplicação (briga DBA x DEV)
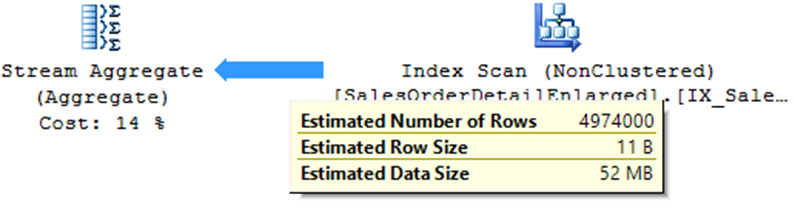
Stream Aggregate
– Consultas com agrupamento (GROUP BY, DISTINCT, etc)
– Operador que costuma ser bem pesado nas consultas
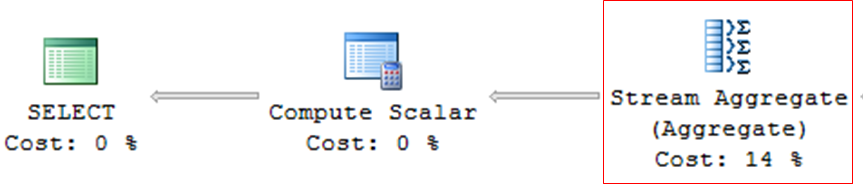
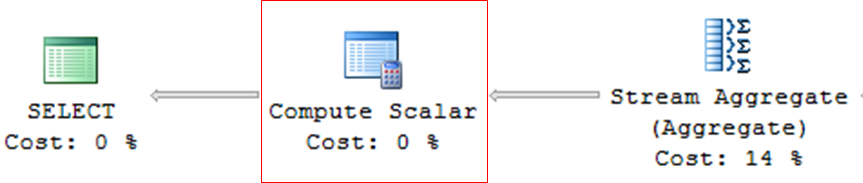
Compute Scalar
– Operador utilizado em consultas com expressões, cálculos matemáticos ou conversões (CAST, CONVERT)
Nested Loops
– Algoritmo muito eficiente
– Ideal para cenários com poucos registros
– Para cada linha da outer table, varre todas na inner table.
– Baixo consumo de CPU e memória
– Variável tabela (@Tabela) SEMPRE vai usar Nested Loops, independente da quantidade de registros, pois como não possui estatísticas, sempre a quantidade estimada de linhas é 1 (a não ser que você force com hint).
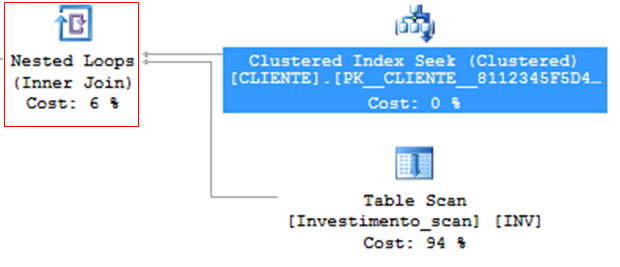
Como funciona internamente:
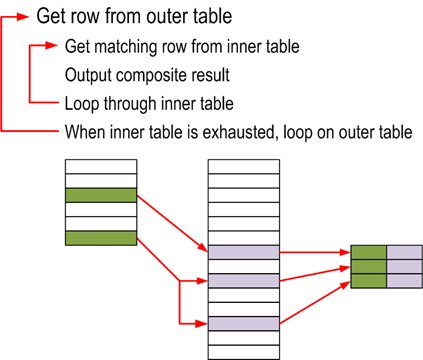
Algoritmo utilizado:
|
1 2 3 4 |
for each row R1 in the outer table for each row R2 in the inner table if R1 joins with R2 return (R1, R2) |
Merge Join
– Eficiente, mas precisa de dados ordenados
– Ideal para cenários com muitos registros
– Se os dados não estiverem ordenados o Merge Join pode requerer a ordenação através de um Sort Merge Join
– Se ambas tabelas não tiverem índice único, ocorre Merge Join Many to Many – tabelas sem PK, utiliza tempdb, menos eficiente
– Merge Join e seu impacto na TEMPDB – Consumo muito mais alto que o Nested Loop, pois os matches são feitos em memória e o volume de dados costuma ser maior também.
– Em geral consome pouca CPU e memória. Encontrado com frequência em consultas com covering indexes.
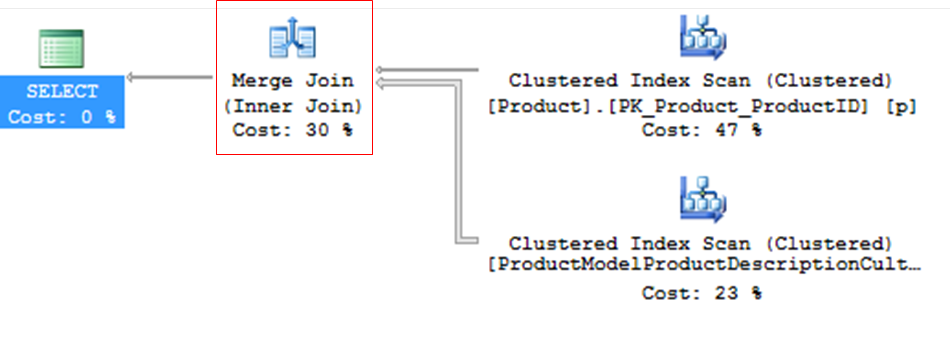
Como funciona internamente:
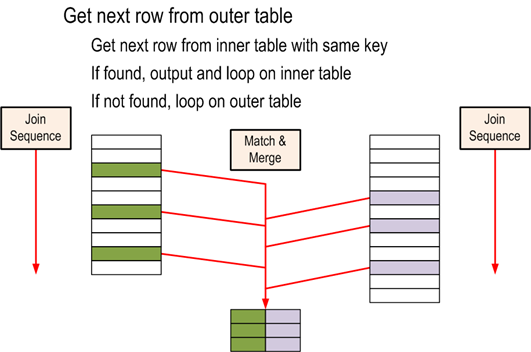
Algoritmo utilizado:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
get first row R1 from input 1 get first row R2 from input 2 while not at the end of either input begin if R1 joins with R2 begin return (R1, R2) get next row R2 from input 2 end else if R1 < R2 get next row R1 from input 1 else get next row R2 from input 2 end |
Algumas dicas para Troubleshooting
– Lookup: Resolva com Covering index ou INCLUDE
– Index Scan pode ser reflexo de um Lookup caro! Preste atenção!
– Cuidado com as Conversões, especialmente conversões na cláusula WHERE. Elas podem ser mortais para a sua consulta!
– Preste atenção nas estatísticas desatualizadas: Número estimado <> número atual

– Parameter sniffing: Ocorre quando uma mesma SP possui diversos tipos de comportamentos de acordo com os parâmetros informados, fazendo com que o plano utilizado não seja o adequado. Tente criar procedures diferentes para cada parâmetro ou adicionar cláusula WITH RECOMPILE ou Hint OPTION (RECOMPILE).
Bom, é isso aí, pessoal!
Esse post é apenas uma introdução na “arte” do Performance Tuning e já estava devendo há uns 3 meses, quando fiz minha palestra no 2º encontro do SQL Server ES e não fiz esse post para complementar a apresentação para quem não foi.
Espero estar voltando em breve com novos posts sobre esse assunto, que acho tão interessante.
Um abraço e até a próxima!
Bom dia a todos!
Dirceu, estou iniciando e tenho muito que te agradecer, parabéns, com simplicidade você nos deixou esta dica um grande tesouro de conhecimento e clareza.
Conheci este site hoje .. ótimo conteúdo .. parabéns ..
Obrigado Erice! Qualquer dúvida, estou à disposição.
Obrigado por compartilhar conhecimento!