- SQL Server – Introdução ao estudo de Performance Tuning
- Entendendo o funcionamento dos índices no SQL Server
- SQL Server – Como identificar uma query lenta ou “pesada” no seu banco de dados
- SQL Server – Dicas de Performance Tuning: Conversão implícita? NUNCA MAIS!
- SQL Server – Comparação de performance entre Scalar Function e CLR Scalar Function
- SQL Server – Dicas de Performance Tuning: Qual a diferença entre Seek Predicate e Predicate?
- SQL Server – Utilizando colunas calculadas (ou colunas computadas) para Performance Tuning
- SQL Server – Como identificar e coletar informações de consultas demoradas utilizando Extended Events (XE)
- SQL Server – Como identificar todos os índices ausentes (Missing indexes) de um banco de dados
- SQL Server e Azure SQL Database: Como Identificar ocorrências de Key Lookup através da plancache
Fala galera!
Mais uma dica de Performance Tuning para vocês, onde vou explicar e comentar a diferença entre Seek Predicate e Predicate, onde podem parecer a mesma coisa, mas fazem uma grande diferença na performance das suas consultas.
Acredito que esse artigo deve responder uma dúvida muito comum de quem está iniciando na área agora: A ordem das colunas na criação do índice faz diferença ? Após ler todo o artigo, comente aqui abaixo qual a sua opinião.. rs
Criando a base de demonstração desse artigo
Para criar essa tabela de exemplo parecida com a minha (os dados são aleatórios, né.. rs), para conseguir acompanhar o artigo e simular esses cenários, você pode utilizar o script abaixo:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 |
IF (OBJECT_ID('dbo.Vendas') IS NOT NULL) DROP TABLE dbo.Vendas CREATE TABLE dbo.Vendas ( Id_Pedido INT IDENTITY(1,1), Dt_Pedido DATETIME, [Status] INT, Quantidade INT, Valor NUMERIC(18, 2) ) CREATE CLUSTERED INDEX SK01_Pedidos ON dbo.Vendas(Id_Pedido) CREATE NONCLUSTERED INDEX SK02_Pedidos ON dbo.Vendas ([Status], Dt_Pedido) INCLUDE(Quantidade, Valor) GO INSERT INTO dbo.Vendas ( Dt_Pedido, [Status], Quantidade, Valor ) SELECT DATEADD(SECOND, (ABS(CHECKSUM(PWDENCRYPT(N''))) / 2147483647.0) * 199999999, '2015-01-01'), (ABS(CHECKSUM(PWDENCRYPT(N''))) / 2147483647.0) * 9, (ABS(CHECKSUM(PWDENCRYPT(N''))) / 2147483647.0) * 10, 0.459485495 * (ABS(CHECKSUM(PWDENCRYPT(N''))) / 2147483647.0) * 1999 GO 10000 INSERT INTO dbo.Vendas ( Dt_Pedido, [Status], Quantidade, Valor ) SELECT Dt_Pedido, [Status], Quantidade, Valor FROM dbo.Vendas GO 9 |
Qual a diferença entre Seek Predicate e Predicate?
Conforme eu expliquei no artigo Entendendo o funcionamento dos índices no SQL Server, o SQL possui 2 formas básicas de leitura à dados:
- Seek: Leitura direta nos ponteiros dos registros de dados que atendem aos critérios da busca. Como os dados estão ordenados (caso não haja fragmentação), é simples utilizar algoritmos de busca rápida, como QuickSort, para ler os dados desejados com poucas leituras no disco.
- Scan: Leitura que pode ser feita utilizando Range Scan (caso exista índice, mas fragmentados), lendo os registros que estão em determinado(s) intervalo(s) ou Full Scan, caso o nível de fragmentação dos registros seja muito alta ou não haja índices, onde o SQL Server terá que ler a tabela inteira até encontrar todos os registros que atendam aos critérios da busca
Pois bem, entendida a explicação bem simples e resumida dessas 2 operações, ficou bem claro que a operação Seek, em índices Rowstore, quase sempre (não é sempre) tem uma performance superior à leitura Scan. Então vamos falar agora sobre o Seek Predicate e o Predicate, que só ocorrem quando a tabela possui índices que atendam à uma determinada consulta.
Seek Predicate é o primeiro filtro que é aplicado aos dados quando o SQL Server executa uma consulta. Por conta disso, o ideal é que os índices sejam criados para priorizar o Seek Predicate nas colunas mais seletivas possíveis (menor quantidade possível de registros para cada valor da coluna), para que o primeiro nível de filtragem retorna a menor quantidade possível de linhas. A operação de Predicate ocorre após o Seek Predicate. Após o primeiro filtro realizado nos dados, o SQL Server irá aplicar os demais filtros da consulta no subconjunto retornado pelo Seek Predicate, ou seja, quanto maior o subconjunto na 2ª etapa, maior o trabalho para o otimizador de consultas, já que no Predicate podem ter filtros que são pesados e não muito seletivos.
Ah, mas como faço para forçar várias condições no Seek Predicate? Não faz.. rs.. Existe um número bem limitado de operações que podem ser feitas em conjunto dentro do Seek Predicate, como por exemplo, uma operação de range (between ou > valor e < valor) e outra de igualdade (=) podem ser utilizadas junto no Seek Predicate, mas duas operações iguais, sejam elas range ou igualdade, não.
Analisando a seletividade das colunas pelo Histograma
Vou demonstrar no exemplo abaixo, com duas operações de range na mesma consulta, como identificar o quão seletivo são as colunas de um determinado índice:
|
1 2 3 4 5 |
SELECT * FROM dbo.Vendas WHERE Dt_Pedido >= '2019-02-06' AND Dt_Pedido < '2019-02-09' AND [Status] < 5 |
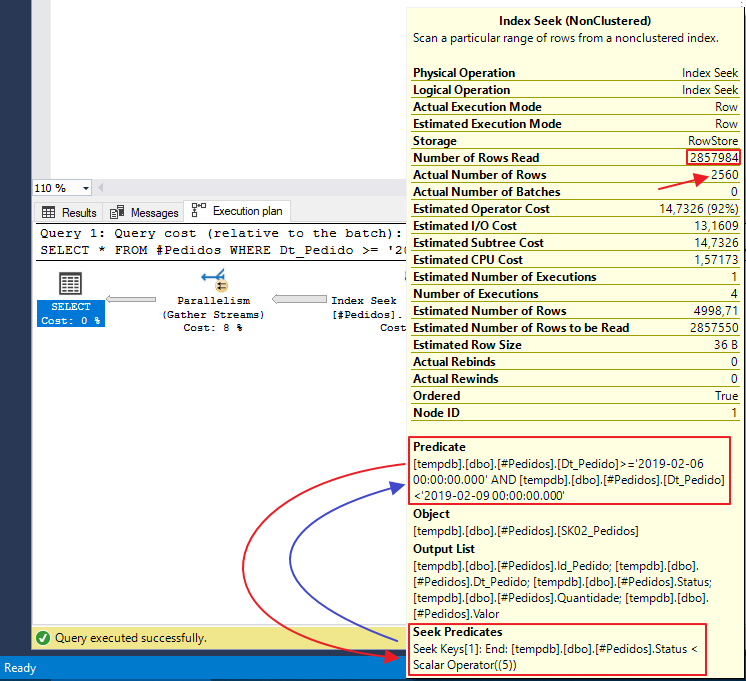
Analisando o plano de execução superficialmente, não identificamos nada de diferente de uma consulta otimizada.. Operação de Seek, nenhum Keylookup.. Tudo certo.

Mas e se a gente analisar mais a fundo ? Bom, não está tão bem assim.. Para retornar 2.560 linhas, eu tive que ler 2.857.984 linhas, mais de 1000x.
Uma outra forma de visualizar como a consulta está sendo executada no banco, é utilizar o comando SET STATISTICS PROFILE ON:

Retornando a seguinte análise no campo StmtText:
|
1 2 3 4 5 6 7 8 9 10 |
SELECT [Quantidade]*[Valor] FROM [dbo].[Vendas] WHERE [Dt_Pedido]>=@1 AND [Dt_Pedido]<@2 AND [Status]<@3 |--Compute Scalar(DEFINE:([Expr1003]=CONVERT_IMPLICIT(numeric(10,0),[dirceuresende].[dbo].[Vendas].[Quantidade],0)*[dirceuresende].[dbo].[Vendas].[Valor])) |--Parallelism(Gather Streams) |--Index Seek(OBJECT:([dirceuresende].[dbo].[Vendas].[SK02_Pedidos]), SEEK:([dirceuresende].[dbo].[Vendas].[Status] < CONVERT_IMPLICIT(int,[@3],0)), WHERE:([dirceuresende].[dbo].[Vendas].[Dt_Pedido]>=CONVERT_IMPLICIT(datetime,[@1],0) AND [dirceuresende].[dbo].[Vendas].[Dt_Pedido]<CONVERT_IMPLICIT(datetime,[@2],0)) ORDERED FORWARD) OBJECT:([dirceuresende].[dbo].[Vendas].[SK02_Pedidos]), SEEK:([dirceuresende].[dbo].[Vendas].[Status] < CONVERT_IMPLICIT(int,[@3],0)), WHERE:([dirceuresende].[dbo].[Vendas].[Dt_Pedido]>=CONVERT_IMPLICIT(datetime,[@1],0) AND [dirceuresende].[dbo].[Vendas]. [dirceuresende].[dbo].[Vendas].[Quantidade], [dirceuresende].[dbo].[Vendas].[Valor] |
Onde o SEEK é o Seek Predicate e o WHERE é o Predicate.
Observem novamente o plano de execução e vejam as condições de Seek Predicate (filtro por Status) e Predicate (filtro por Dt_Pedido). Será que a coluna Status é mais seletiva que a coluna de Dt_Pedido, ainda mais na consulta acima ? Vamos descobrir criando estatística para a coluna de Status e analisar o histograma:
|
1 2 3 4 5 |
CREATE STATISTICS Vendas_Status ON dbo.Vendas(Status) WITH FULLSCAN GO DBCC SHOW_STATISTICS('Vendas', Vendas_Status) GO |
Result:
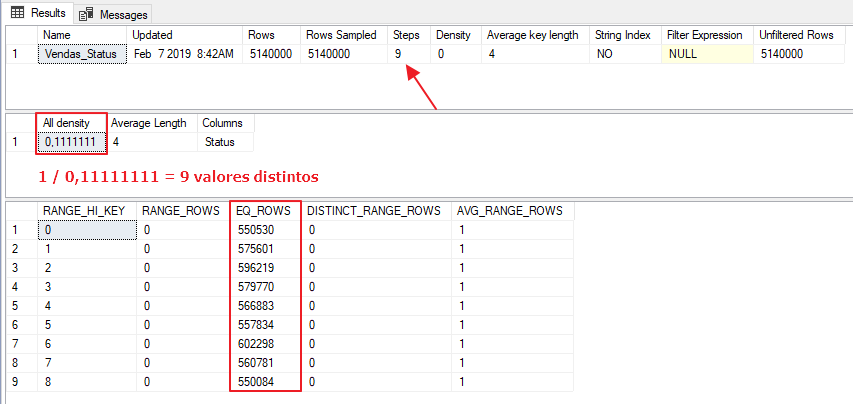
Ou seja, existem apenas 9 valores distintos para a coluna Status, com uma distribuição média entre 550 a 600 mil registros para cada status, como mostra o Histograma. Vamos analisar agora o histograma da coluna Dt_Pedido, para verificar se ela é mais seletiva que a coluna de Status:
|
1 2 3 4 5 |
CREATE STATISTICS Vendas_DtPedido ON dbo.Vendas(Dt_Pedido) WITH FULLSCAN GO DBCC SHOW_STATISTICS('Vendas', Vendas_DtPedido) GO |
Result:
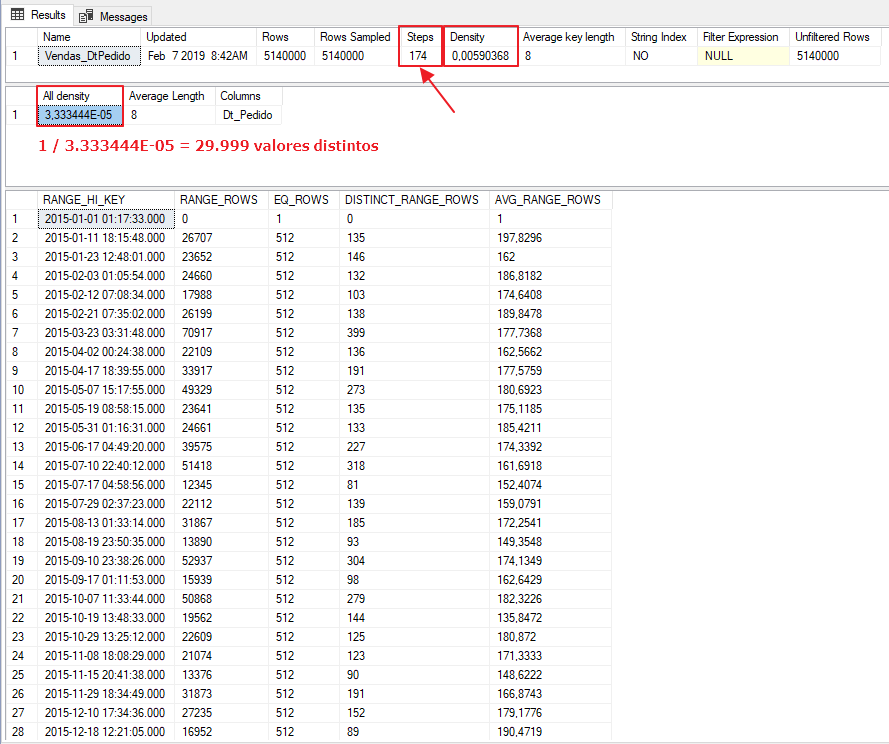
Analisando o histograma da coluna Dt_Pedido, podemos observar que a densidade é muito maior, com cerca de 29.999 valores distintos e uma média de 20 a 50 mil registros para caixa faixa do histograma e uma estimativa de 512 registros por valor distinto, o que mostra que é uma coluna muito mais seletiva que a coluna Status.
Seek Predicate vs Predicate
Agora que já expliquei o funcionamento básico do Seek Predicate e Predicate e como identificar a seletividade de colunas, vou demonstrar alguns exemplos de como podemos tentar identificar e até controlar as operações de Seek Predicate e Predicate.
Relembrando os índices da nossa tabela:
CREATE CLUSTERED INDEX SK01_Pedidos ON dbo.Vendas(Id_Pedido)
CREATE NONCLUSTERED INDEX SK02_Pedidos ON dbo.Vendas([Status], Dt_Pedido) INCLUDE(Quantidade, Valor)
Exemplo 1 – Range e Range
Nesse primeiro exemplo, vou utilizar uma consulta com 2 cláusulas de range (< e/ou >) e vamos tentar controlar o Seek Predicate e o Predicate para essas consultas:
|
1 2 3 4 5 |
SELECT Quatidade * Valor FROM dbo.Vendas WHERE Dt_Pedido >= '2019-02-06' AND Dt_Pedido < '2019-02-09' AND [Status] < 5 |
Resultado da análise do plano de execução:
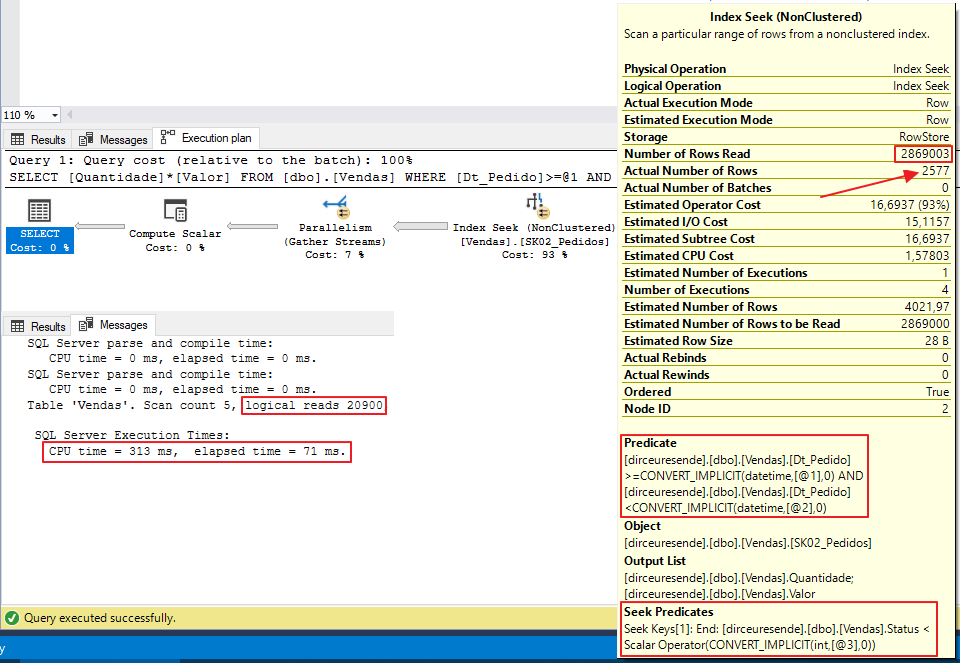
Como já expliquei no tópico anterior, o grau de seletividade da coluna Dt_Pedido é muito maior que o da coluna Status, e isso justifica a quantidade enorme de linhas que foram lidas (2.869.003) para retornar apenas 2.577 registros pela consulta. Embora a operação de leitura seja um Seek, ela ainda pode ser melhorada recriando um índice utilizando uma abordagem mais seletiva.
Para fazer isso, vamos dropar o índice SK02_Pedidos e inverter as colunas desse índice para fazer com que a operação de Seek Predicate seja feita na coluna Dt_Pedido ao invés da coluna Status.
|
1 2 3 4 5 |
DROP INDEX SK02_Pedidos ON dbo.Vendas GO CREATE NONCLUSTERED INDEX SK02_Pedidos ON dbo.Vendas (Dt_Pedido, [Status]) INCLUDE(Quantidade, Valor) GO |
E agora vamos executar a consulta novamente e analisar o plano de execução:
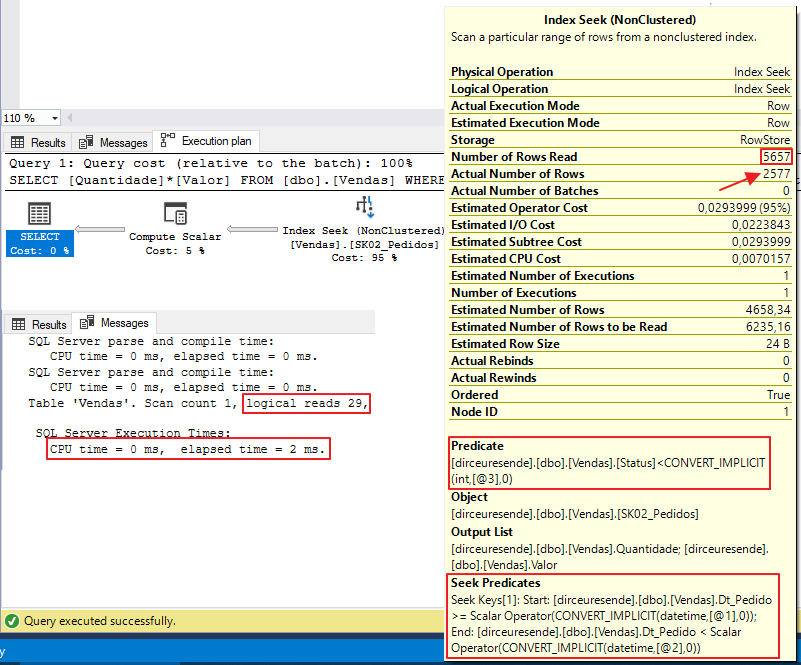
Wow! Que diferença! Olhem que além da nossa consulta utilizar 0ms de CPU (antes era 313ms) e ser executada em apenas 2ms (eram 71ms), a quantidade logical reads caiu de 20.900 para 29 e também a quantidade de linhas lidas caiu de 2.869.003 para 5.657. Tudo isso com apenas uma alteração na ordem dos índices, o que mudou as colunas que fazem parte do Seek Predicate e Predicate.
Exemplo 2 – Range e Igualdade
E se ao invés do status < 5 fosse status = 5, por exemplo? Como ficaria o plano de execução ?
Nova consulta:
|
1 2 3 4 5 |
SELECT Quantidade * Valor FROM dbo.Vendas WHERE Dt_Pedido > '2019-02-06' AND Dt_Pedido < '2019-02-09' AND [Status] = 5 |
Análise do plano de execução com a nova consulta:
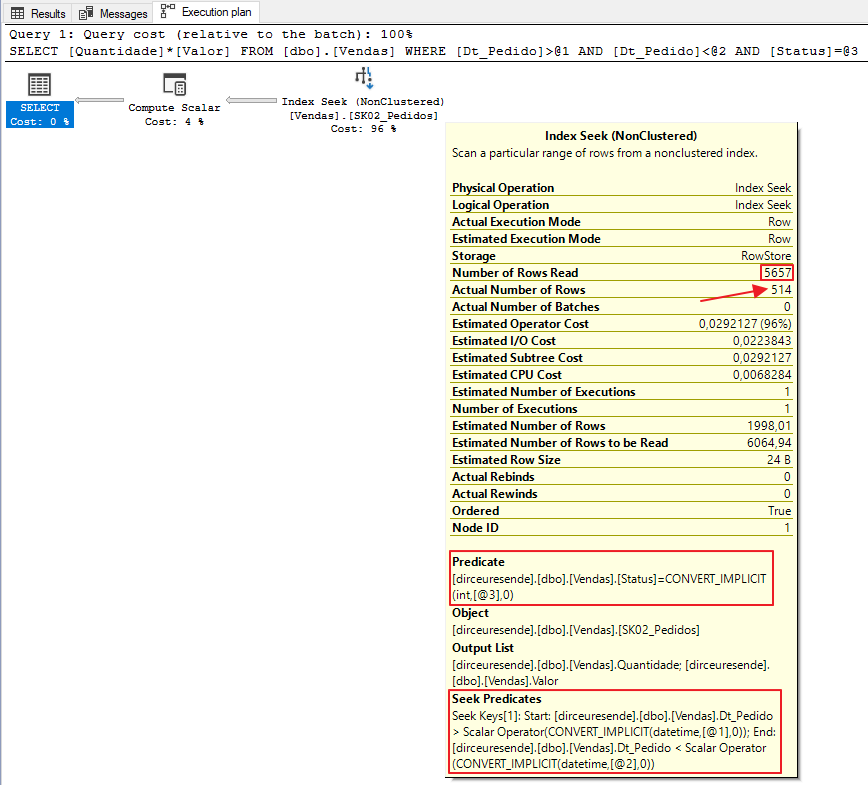
Ou seja, o plano ficou bem parecido com o plano anterior, mesmo alterando o filtro de status. Mas agora vem a pergunta: Dá pra melhorar ainda mais essa consulta ?
Bom, dá sim.. Vamos voltar o índice para a condição anterior.. kkkkkkkk
|
1 2 3 4 5 |
DROP INDEX SK02_Pedidos ON dbo.Vendas GO CREATE NONCLUSTERED INDEX SK02_Pedidos ON dbo.Vendas ([Status], Dt_Pedido) INCLUDE(Quantidade, Valor) GO |
Novo plano gerado pela execução:
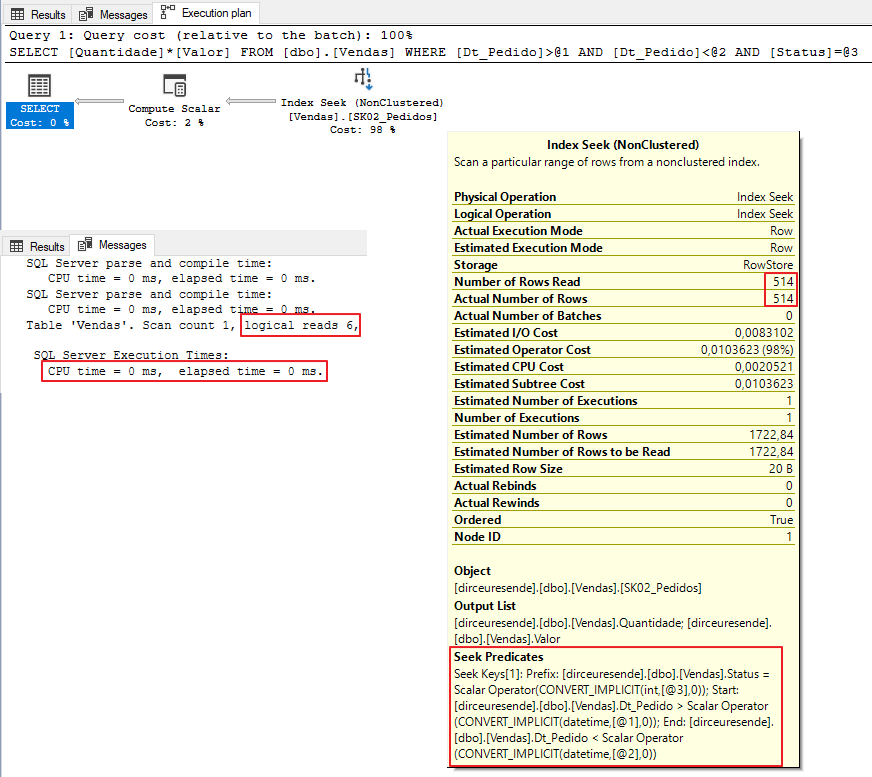
E com o nosso índice antigo, a nossa consulta ficou ainda melhor e mais seletiva! Como sempre falo em Performance, tudo tem que ser testado e avaliado.. Nesse caso, uma das 2 consultas ficará prejudicada pela alteração no índice, ou você pode ter os 2 índices criados (consumindo o dobro de espaço em disco) e forçar o melhor índice para cada situação.
É muito importante observar que a criação de índices deve ser muito bem pensada, porque não dá pra ficar criando índice pra qualquer consulta do banco. Índices ocupam espaço e deixam operações de escritas mais lentas e complexas para o SQL Server, então devem ser criados quando necessário.
Além disso, o trabalho de Performance exige foco em negócio: Os níveis mais altos da empresa não se importam com logical reads ou tempo de execução e sim em como isso agrega valor para o dia a dia da empresa. Não adianta nada gastar seu tempo melhorando uma SP que é executada 1x por dia, de madrugada, e passou a rodar em 1s e antes era 1h, pois não está melhorando em nada a operação da empresa. Procure sempre as melhores oportunidades para a empresa, deixando um pouco de lado somente a visão técnica. Quando você tiver um tempo e o ambiente normalizado, aí você procura melhorar essas rotinas mais pesadas.
And that's it, folks!
Espero que tenham gostado desse post e até mais!
Referências:
Dirceu, criar um predicado de busca artificial é muito útil quando temos uma cláusula WHERE repleta de predicados non sargable. Desta forma é possível transformar leitura sequencial (scan) em busca rápida (seek). No item 4 do artigo “Construindo códigos T-SQL eficientes: Sargability” há exemplo de utilização dessa abordagem para agilizar a execução de uma consulta.
Beleza, obrigado por compartilhar, José