Hey Guys!
Tudo tranquilo?
Neste artigo, gostaria de compartilhar com vocês um problema que tive recentemente, o qual várias colunas, de várias tabelas de um determinado database utilizavam uma collation diferente do padrão do DB, fazendo com que ao realizar joins e condições WHERE entre colunas VARCHAR/CHAR/NVARCHAR com collations diferentes, o banco nos retorne a seguinte mensagem de erro:
O que é uma COLLATION?
O Collation nada mais é do que a forma de codificação de caracteres que um banco de dados utiliza para interpretá-los.
Um Collation é um agrupamento desses caracteres em uma determinada ordem (cada Collation tem uma ordem diferente), onde o “A” é um caracter diferente do “a”, caso o collation seja case-sensitive (diferenciação de maiúsculos e minúsculos) e o “a” é diferente do “á”, caso o collation seja Accent-Sensitive (diferenciação de acentos).
O COLLATION possui três níveis de hierarquia:
– Servidor
– Database
– Coluna
Caso o database seja criado sem especificar qual a collation que será utilizada, ele será criado com a collation do servidor (idioma do sistema operacional). Quando uma tabela é criada sem especificar o collation das colunas de texto (VARCHAR, NVARCHAR, CHAR, etc), o collate do database será utilizado como o collation das tabelas.
No SQL Server, o nome da Collation segue o seguinte padrão de nomeclatura:
SQL_CollationDesignator_CaseSensitivity_AccentSensitivity_KanatypeSensitive_WidthSensitivity
Exemplo de Collation:
SQL_Latin1_General_CP1_CS_AS
Onde:
- CollationDesignator: Especifica as regras de agrupamento básicas usadas pelo agrupamento do Windows, onde as regras de classificação são baseadas no alfabeto ou no idioma.
- CaseSensitivity: CI especifica que não diferencia maiúsculas de minúsculas, CS especifica que diferencia maiúsculas de minúsculas.
- AccentSensitivity: AI especifica que não diferencia acentos, AS especifica que diferencia acento.
- KanatypeSensitive: Omitido especifica que não faz distinção de caracteres kana, KS especifica que faz distinção de caracteres kana.
- WidthSensitivity: Omitido especifica que não distingue largura, WS especifica que distingue largura.
Se uma coluna estiver utilizando uma COLLATION case sensitive (CS), uma query como SELECT * FROM Tabela WHERE Coluna LIKE ‘%Oracle%’ irá retornar o registro “Oracle”, mas não irá retornar o registro “oracle”.
A mesma coisa acontece com uma coluna utilizando um COLLATION accent sensitive (AS). Uma query como SELECT * FROM Tabela WHERE Coluna LIKE ‘%JOÃO%’ irá retornar o registro “João”, mas não irá retornar o registro “Joao”.
Para verificar a lista completa de Collations por região e idioma, acesse este link, lembrando que o mais utilizado no idioma Português (Brasil) é o SQL_Latin1_General_CP1_CI_AI (ou SQL_Latin1_General_CP1_CS_AS).
Para saber mais sobre o que é Collation, dê uma olhada no artigo SQL Server – Cannot resolve the collation conflict between … in the equal to operation..
Como identificar a collation padrão?
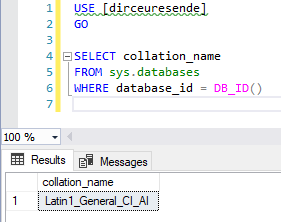
Para identificar a collation padrão de um database, basta utilizar a query abaixo:
|
1 2 3 4 5 6 |
USE [dirceuresende] GO SELECT collation_name FROM sys.databases WHERE database_id = DB_ID() |
Result:
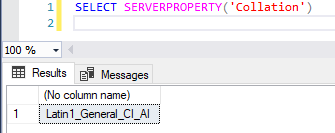
Para identificar a collation padrão da sua instância, basta utilizar o comando abaixo:
|
1 |
SELECT SERVERPROPERTY('Collation') |
Result:
Geração da base para os testes
Para padronizar os exemplos e ajudar no entendimento prático desse artigo, vou utilizar um script simples para gerar dados de exemplo (testes):
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 |
------------------------------------------------------------------------ -- Geração dos dados para teste ------------------------------------------------------------------------ CREATE TABLE dbo.Cliente ( CPF VARCHAR(11) COLLATE Latin1_General_CS_AS NOT NULL PRIMARY KEY CLUSTERED, Name VARCHAR(50) ) INSERT INTO dbo.Cliente ( CPF, Name ) VALUES ( '12345678909', 'Joãozinho' ) CREATE NONCLUSTERED INDEX SK01 ON dbo.Cliente(CPF) INCLUDE(Name) CREATE TABLE dbo.Pedido ( Id INT IDENTITY(1,1) NOT NULL PRIMARY KEY CLUSTERED, Dt_Pedido DATETIME DEFAULT GETDATE(), Vl_Pedido MONEY, CPF_Cliente VARCHAR(11) COLLATE Latin1_General_CS_AS CONSTRAINT [FK_Cliente] FOREIGN KEY(CPF_Cliente) REFERENCES dbo.Cliente(CPF) NOT NULL ) INSERT INTO dbo.Pedido ( Vl_Pedido, CPF_Cliente ) VALUES ( 9.99, -- Vl_Pedido - money '12345678909' -- Id_Cliente - int ) CREATE NONCLUSTERED INDEX SK02 ON dbo.Pedido(Id, Dt_Pedido, CPF_Cliente) |
Como padronizar a collation de todas as colunas?
Caso você queira padronizar a collation de todas as colunas de um database, de modo que elas utilizem uma collation específica ou a padrão do database, desenvolvi um script que irá identificar todas as colunas que estão fora do padrão e irá executar um comando de ALTER TABLE para aplicar a alteração.
Como existem dependências (constraints, índices e foreign keys), o script irá dropar os objetos dependentes identificados, aplicar as alterações e recriar esses objetos. Por conta disso, recomendo fortemente que você teste bem antes de executar esse script em produção. De preferência, faça um backup de estrutura antes.
Script para alterar a collation de todas as colunas (e dependências) que estejam com o Collation diferente do database
Visualizar código-fonte
Script para alterar o collation de todas as colunas (e dependências) de acordo com o Collation desejado:
Visualizar código-fonte
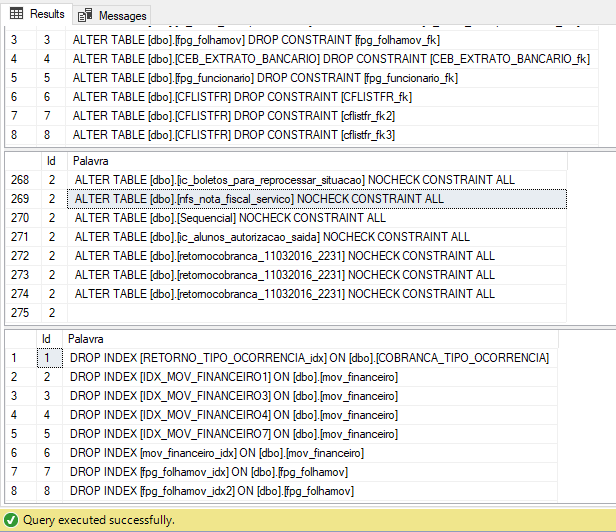
Result:

Caso o script identifique muitas colunas para alterar e a saída do PRINT esteja ficando cortada por causa do tamanho das strings geradas, você pode utilizar a função fncSplitTexto, que disponibilizei no post Como quebrar um string em uma tabela de substrings utilizando um delimitador no SQL Server e substituir o final do script por esse trecho aqui:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 |
------------------------------------------------------------------------- -- Executa os scripts ------------------------------------------------------------------------- PRINT '---------- Dropando as contraints FK' IF (NULLIF(LTRIM(RTRIM(@CmdDropFK)), '') IS NOT NULL) SELECT * FROM dirceuresende.dbo.fncSplitTexto(@CmdDropFK, ';') IF (@Fl_Debug = 0) EXEC(@CmdDropFK) PRINT '---------- Desativando as Check Contraints' IF (NULLIF(LTRIM(RTRIM(@CmdDisableCK)), '') IS NOT NULL) SELECT * FROM dirceuresende.dbo.fncSplitTexto(@CmdDisableCK, ';') IF (@Fl_Debug = 0) EXEC(@CmdDisableCK) PRINT '---------- Dropando os índices' IF (NULLIF(LTRIM(RTRIM(@CmdDropIndex)), '') IS NOT NULL) SELECT * FROM dirceuresende.dbo.fncSplitTexto(@CmdDropIndex, ';') IF (@Fl_Debug = 0) EXEC(@CmdDropIndex) PRINT '---------- Dropando os índices em constraints' IF (NULLIF(LTRIM(RTRIM(@CmdDropIndexConstraint)), '') IS NOT NULL) SELECT * FROM dirceuresende.dbo.fncSplitTexto(@CmdDropIndexConstraint, ';') IF (@Fl_Debug = 0) EXEC(@CmdDropIndexConstraint) PRINT '---------- Alterando a tabela' IF (NULLIF(LTRIM(RTRIM(@CmdAlterTable)), '') IS NOT NULL) SELECT * FROM dirceuresende.dbo.fncSplitTexto(@CmdAlterTable, ';') IF (@Fl_Debug = 0) EXEC(@CmdAlterTable) PRINT '---------- Reativando as constraints' IF (NULLIF(LTRIM(RTRIM(@CmdEnableCK)), '') IS NOT NULL) SELECT * FROM dirceuresende.dbo.fncSplitTexto(@CmdEnableCK, ';') IF (@Fl_Debug = 0) EXEC(@CmdEnableCK) PRINT '---------- Recriando os índices' IF (NULLIF(LTRIM(RTRIM(@CmdCreateIndex)), '') IS NOT NULL) SELECT * FROM dirceuresende.dbo.fncSplitTexto(@CmdCreateIndex, ';') IF (@Fl_Debug = 0) EXEC(@CmdCreateIndex) PRINT '---------- Recriando os índices em constraints' IF (NULLIF(LTRIM(RTRIM(@CmdCreateIndexConstraint)), '') IS NOT NULL) SELECT * FROM dirceuresende.dbo.fncSplitTexto(@CmdCreateIndexConstraint, ';') IF (@Fl_Debug = 0) EXEC(@CmdCreateIndexConstraint) PRINT '---------- Recriando as FKs' IF (NULLIF(LTRIM(RTRIM(@CmdCreateFK)), '') IS NOT NULL) SELECT * FROM dirceuresende.dbo.fncSplitTexto(@CmdCreateFK, ';') IF (@Fl_Debug = 0) EXEC(@CmdCreateFK) |
Result:
Espero que tenham gostado desse post e até a próxima!
PS: Lembre de fazer o backup e testar BASTANTE se você planeja aplicar esse script em Produção.
Em caso de dúvidas ou problemas, deixe aqui nos comentários.
Dirceu, bom dia! Estou com o mesmo problema relatado pelo Ademir, logo acima. Quando executo seu script, ele executa certinho, porém não altera o collation das colunas.
No resultado, aponta como o script executado com sucesso.
Tem ideia do que pode ser?
Agradeço demais a ajuda.
Erro ao executar o penúltimo script:
Msg 7738, Level 16, State 2, Line 1
Cannot enable compression for object ‘xyz’. Only SQL Server Enterprise Edition supports compression.
Olá amigo, parabéns pela sua aula.. fantástica. Agora eu questiono: e quando você não pode alterar o collate mas precisa usar, por exemplo, consultas em dois bancos diferentes (tabelas com JOIN),as os collates são diferentes.. tem como apenas setar o collate, fazer a consulta, e deixar sem alterar ???
Dirceu,
Se na parte “Executa os scripts” eu comentar as linhas do EXEC -> “IF (@Fl_Debug = 0) EXEC(@CmdDropFK)” poderei ver todos os comandos ALTER TABLE, DROP etc sem que sejam executados? Isto porque tenho um database com muitas colunas fora do padrão da base mas gostaria de arrumar por grupos de tabelas relacionadas, e não todas de uma vez. Assim copiar e colaria dos comandos gerados só os que preciso.
Boa tarde
Muito obrigado pelo script, ajudou muito.
Segue algumas observacoes para ajudar quem precisar:
Se seu banco de dados possuir muitas chaves estrangeiras e voce tentar rodar este script apenas para algumas tabelas, pode ser que as alteracoes nao sejam efetuadas, uma vez que poderá haver chave estrangeira relacionada a tabela executada, porém pertencente a uma tabela do qual não foi relacionada no processamento do script.
– Execute o script sempre para o database todo.
Se estiver rodando este script num sqlserver express, os parametros abaixo devem ser removidos dos comandos de criacao dos indices/constraints:
Se não for removido, os indices não serão recriados porque estes parametros estao disponiveis apenas para versao enterprise do sqlserver.
– DATA_COMPRESSION = PAGE
– SORT_IN_TEMPDB = OFF
Se seu banco de dados for muito grande, as variaveis varchar(max) nao suportão concatenar tanta informacao e a string será cortada quando atingir 8000 caracteres….Para resolver esta questao, criei uma tabela com um campo chamado comando e outro chamado ordem, e alterei o script para ao invés de concatenar nas variaveis, inserir comando a comando nessa tabela de acordo com sua ordem de execucao e entao depois de inserido todos os comandos, criei outro script para varrer comando a comando dessa tabela e executá-lo.
Olá Dirceu.
Agradeço pelo tempo dedicado em disseminar conhecimento.
Eu executei esse procedimento mas infelizmente não funcionou.
O script até alterou collation do SQL SERVER mas DATABASE quero alterar as tabelas não funcionou.
Versão do SQL
Microsoft SQL Server 2012 (SP4) (KB4018073)
Tem alguma dica ?
Olá Dirceu.
Agradeço demais esse post. Porém estou com um problema. Quando executo seu script, ele executa certinho, porém não altera o collation das colunas.
No resultado, aponta como o script executado com sucesso.
Tem ideia do que pode ser?
Agradeço demais a ajuda.
Olá Almedir. Tudo bem?
Ainda está com esse problema? Qualquer coisa me avisa.
Dirceu, boa tarde! Estou exatamente com este problema. Meu SQL Server é o 2019 Standard.
Consegue me ajudar?
De antemão, agradeço imensamente sua ajuda.
Olá Dirceu, boa tarde!
Muito legal o post, porém tenho uma dúvida, no meu caso existem mais de 43mil colunas que precisam ser alteradas, portanto ao rodar o script o resultado do script ultrapassa o máximo permitido pelo campo “message” do management studio e acabo não vendo todos os comandos.
Tem alguma solução?
Obrigado desde já!
Fala Kelvin, beleza ?
Editei o post para responder a sua dúvida..
Qualquer coisa, é só falar!
Muito obrigado Dirceu!