Neste post vou demonstrar a vocês como resolver de forma simples e rápida um problema que apesar de ser simples e a mensagem ser bem clara, já vi muitos analistas não sabendo como resolver.
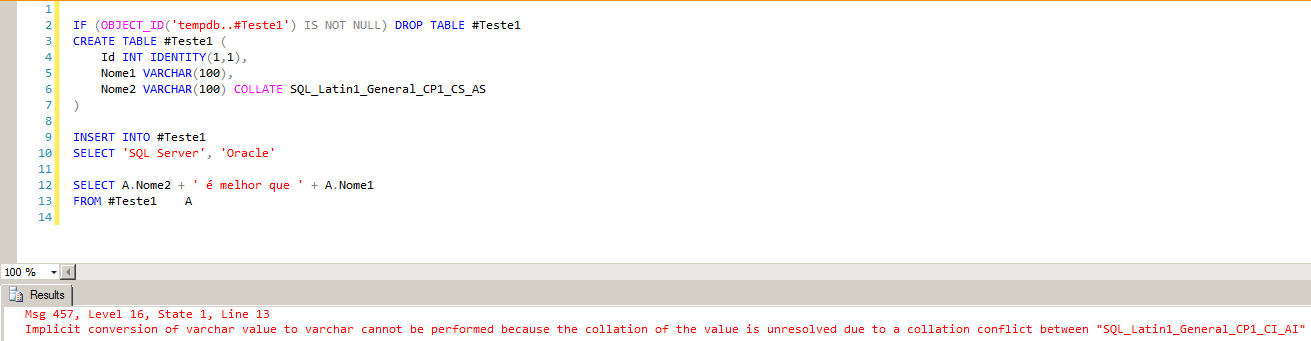
Cannot resolve the collation conflict between “SQL_Latin1_General_CP1_CI_AI” and “SQL_Latin1_General_CP1_CS_AS” in the equal to operation.
O que é uma COLLATION?
O que é uma COLLATION?
O Collation nada mais é do que a forma de codificação de caracteres que um banco de dados utiliza para interpretá-los.
Um Collation é um agrupamento desses caracteres em uma determinada ordem (cada Collation tem uma ordem diferente), onde o “A” é um caracter diferente do “a”, caso o collation seja case-sensitive (diferenciação de maiúsculos e minúsculos) e o “a” é diferente do “á”, caso o collation seja Accent-Sensitive (diferenciação de acentos).
O COLLATION possui três níveis de hierarquia:
– Servidor
– Database
– Coluna
Caso o database seja criado sem especificar qual a collation que será utilizada, ele será criado com a collation do servidor (idioma do sistema operacional). Quando uma tabela é criada sem especificar o collation das colunas de texto (VARCHAR, NVARCHAR, CHAR, etc), o collate do database será utilizado como o collation das tabelas.
No SQL Server, o nome da Collation segue o seguinte padrão de nomeclatura:
SQL_CollationDesignator_CaseSensitivity_AccentSensitivity_KanatypeSensitive_WidthSensitivity
Exemplo de Collation:
SQL_Latin1_General_CP1_CS_AS
Onde:
CollationDesignator: Especifica as regras de agrupamento básicas usadas pelo agrupamento do Windows, onde as regras de classificação são baseadas no alfabeto ou no idioma.
CaseSensitivity: CI especifica que não diferencia maiúsculas de minúsculas, CS especifica que diferencia maiúsculas de minúsculas.
AccentSensitivity: AI especifica que não diferencia acentos, AS especifica que diferencia acento.
KanatypeSensitive: Omitido especifica que não faz distinção de caracteres kana, KS especifica que faz distinção de caracteres kana.
WidthSensitivity: Omitido especifica que não distingue largura, WS especifica que distingue largura.
Se uma coluna estiver utilizando uma COLLATION case sensitive (CS), uma query como SELECT * FROM Tabela WHERE Coluna LIKE ‘%Oracle%’ irá retornar o registro “Oracle”, mas não irá retornar o registro “oracle”.
A mesma coisa acontece com uma coluna utilizando um COLLATION accent sensitive (AS). Uma query como SELECT * FROM Tabela WHERE Coluna LIKE ‘%JOÃO%’ irá retornar o registro “João”, mas não irá retornar o registro “Joao”.
Para verificar a lista completa de Collations por região e idioma, acesse este link, lembrando que o mais utilizado no idioma Português (Brasil) é o SQL_Latin1_General_CP1_CI_AI (ou SQL_Latin1_General_CP1_CS_AS).
Uma forma fácil de simular esse erro é criando uma tabela onde duas ou mais colunas possuem collations diferentes e tentar fazer uma comparação no WHERE entre essas colunas, uma concatenação ou criar duas tabelas com colunas de collations diferentes e tentar realizar um join entre as 2 colunas.
Vale lembrar que esse erro só acontece ao comparar ou manipular duas colunas de TEXTO (VARCHAR, NVARCHAR, CHAR, etc) de collations diferentes.
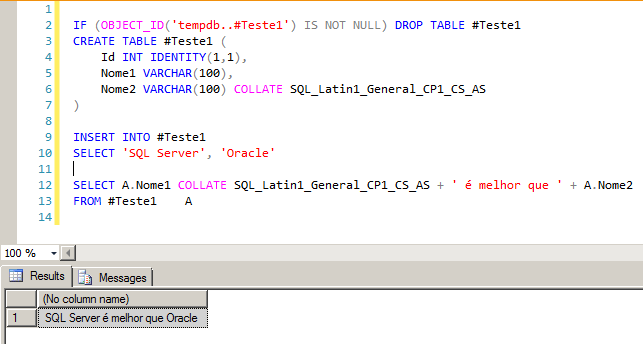
Uma forma simples, rápida e prática para conseguir contornar esse problema de forma provisória ou quando você não tem acesso para alterar a estrutura da tabela/database, é utilizar o operador COLLATE no próprio select, que irá converter todos os dados da coluna para um determinado collation e depois poderá comparar e trabalhar com os dados normalmente.
Transact-SQL
1
2
SELECTA.Nome1COLLATESQL_Latin1_General_CP1_CS_AS+' é melhor que '+A.Nome2
FROM#Teste1A
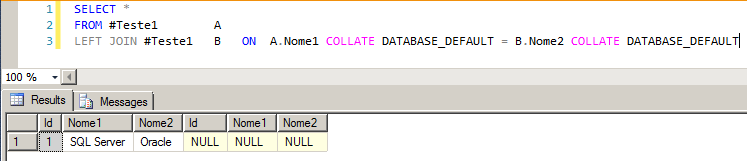
Você ainda pode utilizar o collation DATABASE_DEFAULT nas duas colunas envolvidas, para garantir a compatibilidade entre elas, convertendo as duas colunas para a mesma collation do banco:
Essa é uma solução provisória e de contorno, que não deve ser aplicada em grandes volumes de dados, uma vez que a performance não é ideal, já que toda a coluna precisa ser lida e convertida para depois trabalhar com o dado.
Como identificar o COLLATION do database
Como identificar o COLLATION do database
O primeiro passo ao identificar um problema de conflito de collation entre databases, é identificar primeiro qual o collation dos databases envolvidos para tentar entender se o problema está neste posto. Para se identificar o collation de um database, podemos utilizar o comando sp_helpdb:
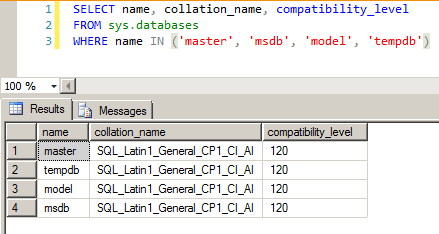
Também podemos utilizar a view de catálogo sys.databases:
Transact-SQL
1
2
3
SELECTname,collation_name,compatibility_level
FROMsys.databases
WHEREnameIN('master','msdb','model','tempdb')
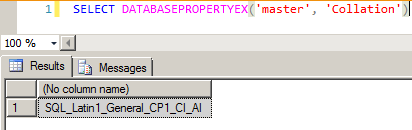
E também utilizar a função DATABASEPROPERTYEX:
Transact-SQL
1
SELECTDATABASEPROPERTYEX('master','Collation')
Como identificar o COLLATION de uma coluna
Como identificar o COLLATION de uma coluna
Após analisar o collation dos databases envolvidos e constatar que já estão utilizando a mesma codificação, vamos analisar agora as colunas envolvidas.
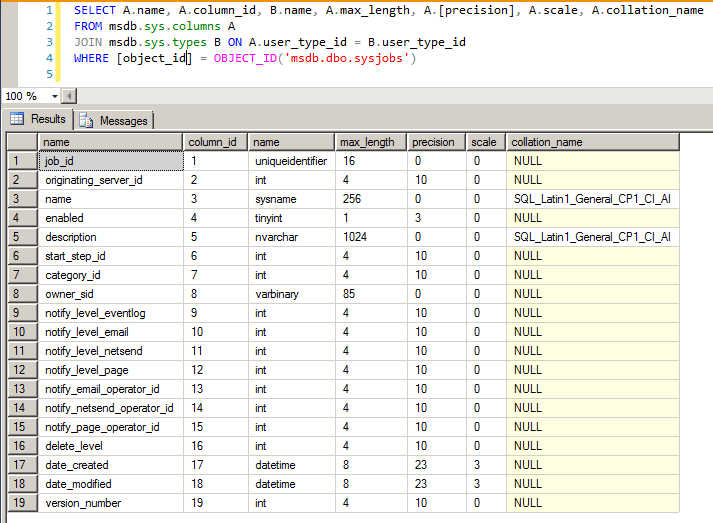
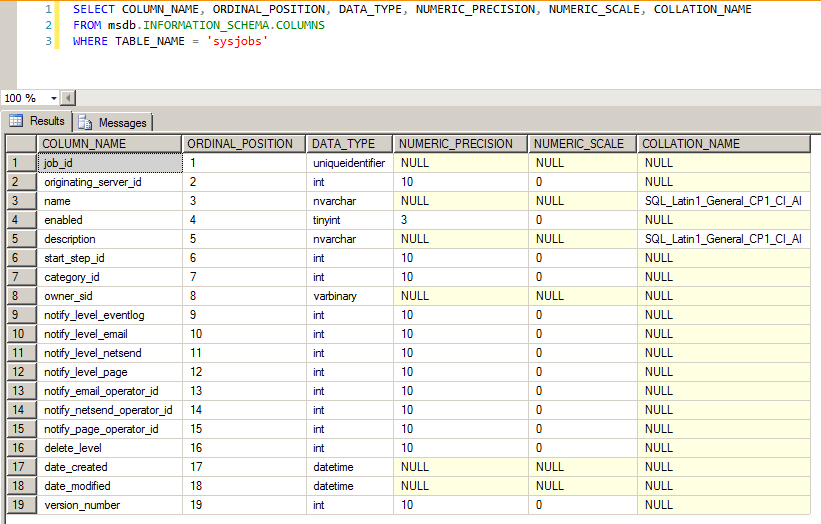
Existem várias formas de realizar essa verificação, como a sys.columns:
Uma solução definitiva para resolver o problema do collation reportado é alterar a coluna que possui a codificação de caracteres diferente do restante, de forma a padronizar a tabela para que todas as colunas utilizem a mesma codificação.
Com esse comando, estamos alterando a coluna Nome2 do nosso exemplo para a mesma collation do database. Caso você necessite, pode alterar a collation para uma de sua escolha, ignorando o collation padrão do database:
Uma outra solução definitiva para esse problema de conflito entre collations, é alterando o collation default do database.
Isso é especialmente útil quando as colunas não possuem definição de collation (utilizando a padrão do database) e você está realizando joins e/ou manipulação com strings entre colunas de databases diferentes, com collations diferentes e está enfrentando esse problema.
Exemplo de comando para alterar o collation do database: