- SQL Server – Introdução ao estudo de Performance Tuning
- Entendendo o funcionamento dos índices no SQL Server
- SQL Server – Como identificar uma query lenta ou “pesada” no seu banco de dados
- SQL Server – Dicas de Performance Tuning: Conversão implícita? NUNCA MAIS!
- SQL Server – Comparação de performance entre Scalar Function e CLR Scalar Function
- SQL Server – Dicas de Performance Tuning: Qual a diferença entre Seek Predicate e Predicate?
- SQL Server – Utilizando colunas calculadas (ou colunas computadas) para Performance Tuning
- SQL Server – Como identificar e coletar informações de consultas demoradas utilizando Extended Events (XE)
- SQL Server – Como identificar todos os índices ausentes (Missing indexes) de um banco de dados
- SQL Server e Azure SQL Database: Como Identificar ocorrências de Key Lookup através da plancache
Olá pessoal,
Bom dia!
Neste post vou comentar sobre a estrutura de índices, que ajudam e muito a otimizar consultas, reduzindo IO e CPU e retornando as informações mais rapidamente. Entretanto, muito cuidado ao criar os índices, uma vez que eles ocupam bastante espaço em disco e se não forem bem modelados, podem não ser tão eficazes.
Introduction
Um índice é uma estrutura em disco associada a uma tabela ou view, que agiliza a recuperação das linhas. Um índice contém chaves criadas de uma ou mais colunas e essas chaves são armazenadas em uma estrutura (árvore B) que habilita o SQL Server a localizar a linha ou as linhas associadas aos valores de chave de forma rápida e eficaz.
Com a criação do índice, o banco de dados irá criar uma estrutura de árvore ordenada para facilitar as buscas, onde o primeiro nível é a raiz, os níveis intermediários contém as árvores de índices e o último nível contém os dados e uma lista duplamente encadeada ligando as páginas de dados, contendo um ponteiro de página anterior e próxima página, conforme imagem abaixo:
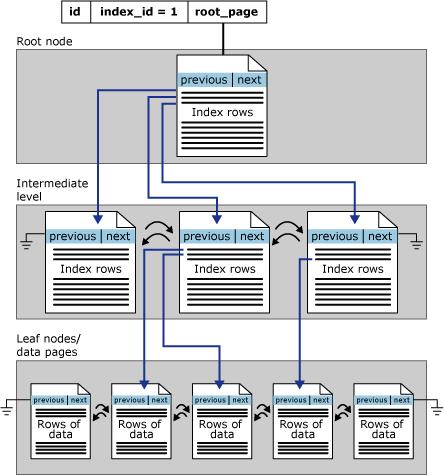
Nem sempre o uso de índice trará um bom desempenho, pois a escolha incorreta de um índice pode causar um desempenho insatisfatório. Portanto, a tarefa do otimizador de consulta é selecionar um índice ou uma combinação de índices apenas quando isso gerar melhoria de desempenho e evitar a recuperação indexada quando isso atrapalhar o desempenho.
A página de dado contém um cabeçalho com índice, com uma lista duplamente encadeada contendo um ponteiro para a página anterior e a próxima, um bloco com os registros (dados) e no rodapé existem os array slots que contém os endereços de memória das páginas com os dados.
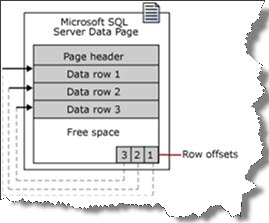
Recomendações na criação de um índice
As seguintes tarefas compõem a estratégia recomendada para criação de índices:
- Entenda as características das consultas mais usadas. Por exemplo, saber que uma consulta usada frequentemente associa duas ou mais tabelas o ajudará a determinar o melhor tipo de índice a ser usado.
- Entenda as características das colunas usadas nas consultas. Por exemplo, um índice é ideal para colunas que tenham um tipo de dados de inteiro e, também, colunas exclusivas ou não nulas. Para colunas que têm subconjuntos bem definido de dados, é possível usar um índice filtrado no SQL Server 2008 e versões posteriores.
- Determine quais opções de índice poderiam aumentar o desempenho na criação ou manutenção do índice. Por exemplo, a criação de um índice clusterizado em uma tabela grande existente se beneficiaria da opção de índice ONLINE. A opção ONLINE permite que atividade simultânea nos dados subjacentes continue enquanto o índice está sendo criado ou reconstruído.
- Determine o melhor local de armazenamento para o índice. Um índice não clusterizado pode ser armazenado no mesmo grupo de arquivos que a tabela subjacente ou em um grupo de arquivos diferente. O local de armazenamento de índices pode melhorar o desempenho de consulta aumentando desempenho de I/O do disco. Por exemplo, o armazenamento de um índice não clusterizado em um grupo de arquivos que está em um disco diferente do grupo de arquivos de tabela pode melhorar o desempenho porque vários discos podem ser lidos ao mesmo tempo.
- Crie índices não clusterizados nas colunas frequentemente usadas em predicados e condições de JOINS em consultas. No entanto, evite adicionar colunas desnecessárias. Acrescentar muitas colunas de índice vai aumentar o espaço em disco e o desempenho de manutenção de índice.
- Cobrindo índices pode melhorar desempenho de consulta porque todos os dados precisaram satisfazer os requisitos da consulta existe dentro do próprio índice. Ou seja, apenas as páginas de índice, e não as páginas de dados da tabela ou do índice clusterizado, são necessárias para recuperar os dados solicitados, portanto reduzindo as operações de E/S gerais do disco. Por exemplo, uma consulta de colunas a e b em uma tabela que tem um índice composto criado em colunas a, b e c pode recuperar os dados especificados somente do índice.
- Escreva consultas que insiram ou modifiquem o máximo de filas possível em uma única instrução, em vez de usar consultas múltiplas para atualizar essas mesmas filas. Ao usar apenas uma instrução, pode-se explorar uma manutenção otimizada do índice.
- Avalie o tipo da consulta e como as colunas são usadas na consulta. Por exemplo, uma coluna usada em uma consulta de correspondência exata seria uma boa candidata para um índice clusterizado ou não clusterizado.
- Mantenha o comprimento da chave de índice curto para os índices clusterizados. Além disso, os índices clusterizados se beneficiam de serem criados em colunas exclusivas ou não nulas.
- Examine a singularidade da coluna. Um índice exclusivo em vez de um índice não exclusivo na mesma combinação de colunas, provê informações adicional para o otimizador de consulta, o que torna o índice mais útil.
- Examine a distribuição de dados na coluna. Frequentemente, uma consulta longa é causada ao se indexar uma coluna com poucos valores exclusivos, ou ao executar uma junção em tal coluna. Por exemplo, uma lista telefônica física ordenada alfabeticamente pelo último nome não será rápida em localizar uma pessoa, se todas as pessoas na cidade tiverem nomes de Smith ou Jones.
- Considere a ordem das colunas se o índice contiver colunas múltiplas. A coluna que é usada na cláusula WHERE em um critério de consulta igual a (=), maior que (>), menor que (>) ou BETWEEN, ou que participa em uma junção, deve ser posicionada primeiro. Colunas adicionais devem ser ordenadas com base em seu nível de distinção, ou seja, do mais distinto ao menos distinto.
Por exemplo, se o índice for definido como LastName, FirstName o índice será útil quando o critério de consulta for WHERE LastName = ‘Smith’ ou WHERE LastName = Smith AND FirstName LIKE ‘J%’. Porém, o otimizador de consulta não usaria o índice para uma consulta que tivesse pesquisado apenas em FirstName (WHERE FirstName = ‘Jane’). - Especifique o fator de preenchimento (Fill Factor) do índice. Quando um índice é criado ou recriado, o valor de fator de preenchimento determina a porcentagem de espaço em cada página de nível folha a ser preenchida com dados, reservando o restante em cada página como espaço livre para futuro crescimento.Por exemplo, a especificação de um valor de fator de preenchimento de 80 significa que 20 por cento de cada página de nível folha ficará vazio, fornecendo espaço para a expansão do índice à medida que dados forem adicionados à tabela subjacente. Um valor de fator de preenchimento corretamente escolhido pode reduzir divisões potenciais de páginas fornecendo espaço suficiente para expansão do índice à medida que são adicionados dados à tabela subjacente. Para saber mais sobre o Fator de preenchimento, acesse este link.
- Considere indexar as colunas computadas.
Índice Clustered ou NonClustered
Índice Clustered
O índice CLUSTERED é montado na própria tabela, criando a estrutura ORDENADA de árvore para facilitar as buscas. Por este motivo, apenas 1 índice desse tipo pode ser criado por tabela e não se pode utilizar INCLUDE de colunas neste tipo de índice. Cada folha do índice cluster possui todas as informações do registro.
Recomendações para a coluna que irá compor o índice clustered:
- Campos numéricos (smallint, tinyint, int, bigint)
- Dados crescentes
- Valores únicos
- Valores que não sofrem updates
- Dados que são utilizados com frequência em buscas, joins, etc
- Geralmente será criado na Primary Key
Exemplo clássico: Dicionário (Você localiza a palavra e junto com ela já tem a definição).
Índice Nonclustered
O índice NONCLUSTERED é uma estrutura ORDENADA à parte, que contém apenas a coluna indexada (e as colunas do INCLUDE, caso exista) e uma tabela pode ter N índices deste tipo. Se for necessário consultar alguma informação que não está no índice NONCLUSTERED, a informação é localizada utilizando o índice clustered da tabela (Key Lookup). Caso a tabela não tenha índice CLUSTERED, será utilizado o IAM (Index Allocation Map) para localizar a informação via RID (RowID – na operação RID Lookup).
Exemplo clássico: Índice de um livro (Você localiza no índice a página onde está o capítulo e depois vai até a página para ver as informações).
Índice composto ou com colunas incluídas
Dúvida muito frequente na criação do índice, essas 2 formas de criação de índice possuem um funcionamento bem diferente:
- Índice composto: É um índice que é formado por mais de uma coluna. Nesse caso, a estrutura de árvore do índice irá ter as informações das colunas que fazem parte do índice em todos os níveis e buscas utilizando esse colunas serão filtradas mais rapidamente.
- Índice com coluna incluída: É um índice formado por uma ou mais colunas e que incluí outras colunas. Nesse caso, a estrutura de árvore do índice será montada apenas com as colunas que fazem parte do índice, e apenas no último nível da árvore (folha), a informação da coluna incluída estará disponível (ocupando menos espaço em disco que o índice composto). Esse tipo de índice é recomendável para evitar operadores de Key Lookup, incluindo as colunas que não fazem parte do índice e que sempre são buscadas, fazendo com que seja utilizado esse índice e também o índice clustered para retornar outras informações.
Quando usar um índice com colunas incluídas
Quando existem colunas utilizadas no SELECT apenas para exibição dos dados, mas que não são utilizadas para filtros, é interessante adicionar essas colunas no INCLUDE, pois as informações ficarão gravadas apenas na nível de folha do índice (último índice), apenas para exibição (por causa isso, esse tipo de índice geralmente é menor que o índice composto).
Caso essas colunas não estejam presentes no índice, será necessário utilizar outro índice (sempre no índice clustered ou no ROWID, caso a tabela não tenha clustered) ou ter que varrer toda a tabela para localizar essas informações. Veja mais detalhes nesse link
Exemplo de criação de índice com coluna incluída
|
1 |
CREATE NONCLUSTERED INDEX SK01 ON dbo.Cliente(CPF) INCLUDE(RG, Name) |
Quando usar o índice composto
Quando uma consulta recorrente utiliza mais de uma coluna na cláusula WHERE, pode ser utilizado índice composto (com mais de uma coluna). Nessa situação, o query plan utiliza o conjunto de colunas para filtrar, de forma que os índices mais restritivos (índices de igualdade) devem vir primeiros na definição, antes dos índices menos restritivos (inigualdades). As outras colunas que compõem o índice são copiadas para todas as folhas da árvore do índice (consumindo mais espaço).
Exemplo de criação de índice composto
|
1 |
CREATE NONCLUSTERED INDEX SK01 ON dbo.Cliente(CPF, RG) |
O que é e como evitar o Key Lookup e o RID Lookup
Quando é realizada uma consulta em uma tabela, o otimizador de consultas do SQL Server irá determinar qual o melhor método de acesso ao dados de acordo com as estatísticas coletada e escolher o que tiver o menor custo.
Como o índice clustered é a própria tabela, gerando um grande volume de dados, geralmente é utilizado o índice não clustered de menor custo para a consulta. Isso pode gerar um problema, pois muitas vezes a query está selecionando colunas onde nem todas estão indexadas, fazendo com que seja utilizado um índice não clustered para a busca das informações indexadas (Index Seek NonClustered) e também seja utilizado o índice clustered para retornar as informações restantes, onde o índice não cluster possui um ponteiro para a posição exata da informação no índice cluster (ou o ROWID, caso a tabela não tenha índice cluster).
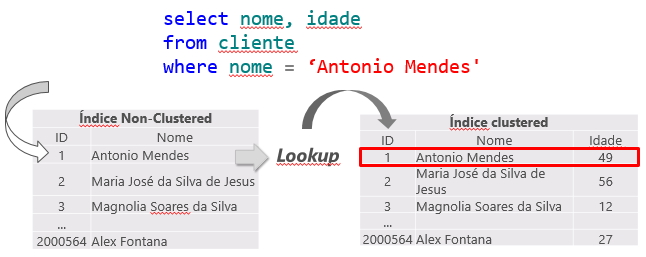
Essa operação é chamada de Key Lookup, no caso de tabelas com índice clustered ou RID Lookup (RID = Row ID) para tabelas que não possuem índice clustered (chamadas tabelas HEAP) e por gerar 2 operações de leituras para uma única consulta, deve ser evitada sempre que possível.
Key Lookup
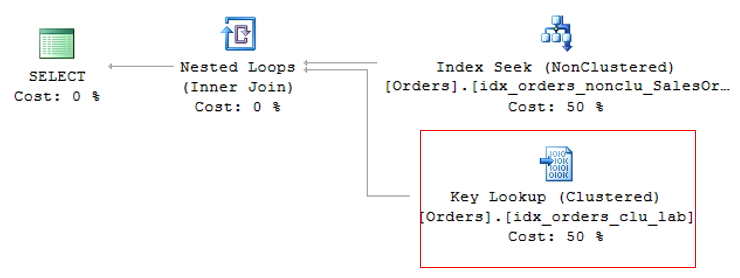
RID Lookup
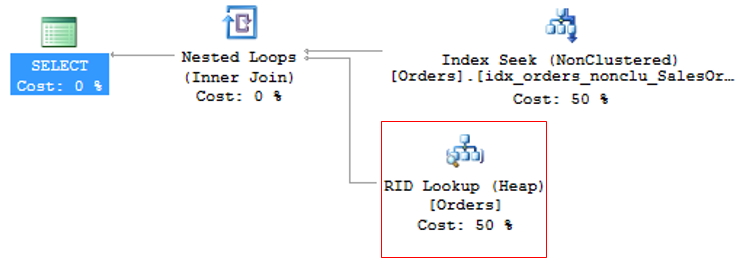
Para evitar o KeyLookup basta utilizar a técnica de cobrir o índice (Covering index), que consiste em adicionar ao índice NonClustered (INCLUDE) as principais colunas que são utilizadas nas consultas à tabela. Isso faz com que o otimizador de consulta consiga obter todas as informações lendo apenas o índice escolhido, sem precisar ler também o índice clustered.
Entretanto, deve-se tomar muita atenção na modelagem dos índices. Não é recomendável adicionar todas as colunas da tabela no índice não cluster, uma vez que ele ficará tão grande que ele não será mais efetivo e o otimizador de consulta poderá até mesmo decidir em não utilizá-lo e preferir o operador Index Scan, que faz a leitura sequencial de todo o índice, prejudicando a performance das consultas.
Para evitar o RID Lookup, basta criar o índice clustered na tabela e prestar atenção aos eventos de Key Lookup que possam vir a surgir.
Índices Únicos (Exclusivos)
Um índice exclusivo garante que a chave de índice não contém nenhum valor duplicado, e então, cada linha na tabela é exclusiva de algum modo.
Índices exclusivos de multicolunas garantem que cada combinação de valores na chave de índice é exclusivo. Por exemplo, se um índice exclusivo for criado em uma combinação de colunas LastName, FirstName e MiddleName, duas linhas na tabela não poderão ter a mesma combinação de valores que essas colunas.
Você não poderá criar um índice exclusivo em uma única coluna se ela tiver NULL em mais de uma linha.Da mesma forma, você não poderá criar um índice exclusivo em várias colunas se a combinação de colunas tiver NULL em mais de uma linha, pois isso é tratado como valores duplicados para fins de indexação.
Internamente, quando se cria uma restrição PRIMARY KEY, é criado automaticamente um índice clusterizado exclusivo na coluna. A grande diferença entre PRIMARY KEY e índice único, é que uma tabela pode possui apenas 1 PRIMARY KEY, mas vários índices únicos.
Exemplo de criação de índice único:
|
1 |
CREATE UNIQUE NONCLUSTERED INDEX SK01 ON dbo.Clientes(CPF) |
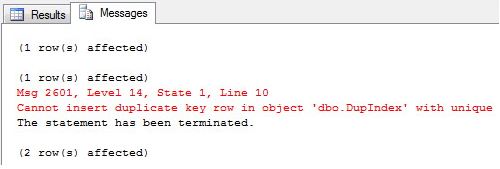
Ao tentar inserir um CPF na tabela de clientes que já exista, será exibido um erro na tela do SQL Server e a execução será abortada:
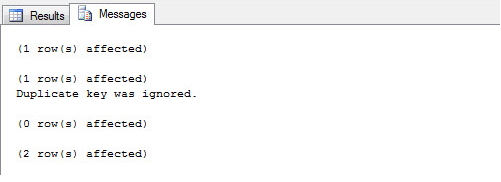
Utilizando o parâmetro IGNORE_DUP_KEY = ON, pode-se permitir que o banco apenas ignore o registro duplicado e apresente apenas um aviso na tela:
|
1 2 |
CREATE UNIQUE NONCLUSTERED INDEX SK01 ON dbo.Clientes(CPF) WITH(IGNORE_DUP_KEY = ON) |
Faça o Rebuild / Reorganize dos índices quando necessário
O Mecanismo de Banco de Dados do SQL Server mantém os índices automaticamente sempre que são realizadas operações de entrada, atualização ou exclusão nos dados subjacentes. No decorrer do tempo, essas modificações podem fazer com que as informações do índice sejam dispersadas pelo banco de dados (fragmentadas). A fragmentação ocorre quando os índices têm páginas nas quais a ordem lógica, com base no valor de chave, não corresponde à ordem física do arquivo de dados. Índices com fragmentação pesada podem degradar o desempenho da consulta e causar lentidão de resposta do aplicativo.
Identificando a fragmentação dos índices
A primeira etapa para optar pelo método de fragmentação a ser usado é analisar o índice para determinar o grau de fragmentação. Usando a função de sistema sys.dm_db_index_physical_stats, você pode detectar a fragmentação em um índice específico, em todos os índices de uma tabela ou exibição indexada, em todos os índices de um banco de dados ou em todos os índices de todos os bancos de dados. Para índices particionados, sys.dm_db_index_physical_stats também fornece informações de fragmentação por partição.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
SELECT OBJECT_NAME(B.object_id) AS TableName, B.name AS IndexName, A.index_type_desc AS IndexType, A.avg_fragmentation_in_percent FROM sys.dm_db_index_physical_stats(DB_ID(), NULL, NULL, NULL, 'LIMITED') A INNER JOIN sys.indexes B WITH(NOLOCK) ON B.object_id = A.object_id AND B.index_id = A.index_id WHERE A.avg_fragmentation_in_percent > 30 AND OBJECT_NAME(B.object_id) NOT LIKE '[_]%' AND A.index_type_desc != 'HEAP' ORDER BY A.avg_fragmentation_in_percent DESC |

Uma vez identificado o nível de fragmentação do índice, pode-se escolher qual o método que será utilizado para desfragmentá-lo:
– REORGANIZE: Utilizado quando o nível de fragmentação está entre 5% e 30%. Esse método não causa indisponibilidade do índice, pois o índice não chega a ser apagado, apenas reorganizado.
– REBUILD: Utilizado quando o nível de fragmentação é superior a 30%. Esse método por padrão causa indisponibilidade do índice, pois apaga e recria o índice novamente. Para que não seja gerada indisponibilidade, pode-se utilizar o parâmetro ONLINE na execução do REBUILD.
Desfragmentando o índice
Desfragmentando um índice fragmentado (REORGANIZE)
|
1 2 |
ALTER INDEX SK01 ON dbo.Logins REORGANIZE |
Desfragmentando todos os índices da tabela (REORGANIZE)
|
1 2 |
ALTER INDEX ALL ON dbo.Logins REORGANIZE |
Desfragmentando todos os índices da tabela (REBUILD)
|
1 2 |
ALTER INDEX ALL ON dbo.Logins REBUILD |
Desfragmentando todos os índices da tabela (REBUILD – COMPLETO)
|
1 2 |
ALTER INDEX ALL ON dbo.Logins REBUILD WITH (FILLFACTOR = 80, SORT_IN_TEMPDB = ON, STATISTICS_NORECOMPUTE = ON, ONLINE = ON) |
Para saber mais sobre Rebuild e Reorganize, acesse este link.
DMV’s e views do catálogo de índices
Segue a lista de DMV’s e views de catálogo de índices que podem ser utilizadas para obter informações de uso e estatísticas dos índices:
DMV’s
- sys.dm_db_column_store_row_group_physical_stats
- sys.dm_db_missing_index_groups
- sys.dm_db_index_operational_stats
- sys.dm_db_index_physical_stats
- sys.dm_db_index_usage_stats
- sys.dm_db_missing_index_columns
- sys.dm_db_missing_index_details
- sys.dm_db_missing_index_group_stats
Views de catálogo
- sys.index_columns
- sys.indexes
- sys.sysindexes
- sys.sysindexkeys
- sys.xml_indexes
Verificar a utilização dos índices
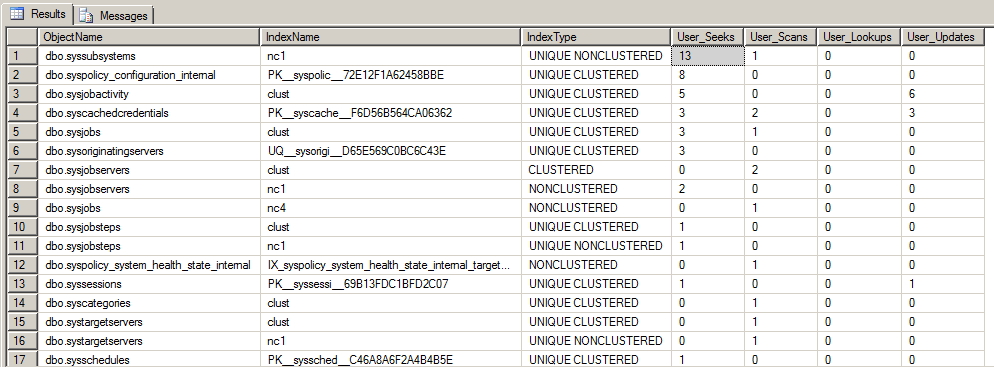
Com a query abaixo, é possível identificar a utilização dos índices no banco, exibindo leituras com Index Seek (índice bem utilizado), Index Scan (Possível problema na modelagem do índice), Lookups e Updates (número de vezes que o índice foi atualizado com novos registros)
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
SELECT ObjectName = OBJECT_SCHEMA_NAME(idx.object_id) + '.' + OBJECT_NAME(idx.object_id), IndexName = idx.name, IndexType = CASE WHEN is_unique = 1 THEN 'UNIQUE ' ELSE '' END + idx.type_desc, User_Seeks = us.user_seeks, User_Scans = us.user_scans, User_Lookups = us.user_lookups, User_Updates = us.user_updates FROM sys.indexes idx LEFT JOIN sys.dm_db_index_usage_stats us ON idx.object_id = us.object_id AND idx.index_id = us.index_id AND us.database_id = DB_ID() WHERE OBJECT_SCHEMA_NAME(idx.object_id) != 'sys' ORDER BY us.user_seeks + us.user_scans + us.user_lookups DESC |
Ajudando a identificar o melhor candidato a índice clustered
Com a query abaixo, é possível deixar o SQL nos ajudar a definir qual o melhor índice candidato a ser o clustered da tabela. Analisando a DMV dm_db_index_usage_stats, a query identifica o índice non-clustered que tenha mais leituras Seek que o clustered (na query, defini um percentual de 150%) e a quantidade de Seeks seja menor que os Lookups do índice clustered.
Não é recomendável utilizar apenas o resultado dessa query para essa definição. Ela deve servir para indicar uma possível melhoria na troca dos índices e o DBA deve fazer a análise detalhada para confirmar essa indicação.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 |
SELECT TableName = OBJECT_NAME(idx.object_id), NonUsefulClusteredIndex = idx.name, ShouldBeClustered = nc.nonclusteredname, Clustered_User_Seeks = c.user_seeks, NonClustered_User_Seeks = nc.user_seeks, Clustered_User_Lookups = c.user_lookups, DatabaseName = DB_NAME(c.database_id) FROM sys.indexes idx LEFT JOIN sys.dm_db_index_usage_stats c ON idx.object_id = c.object_id AND idx.index_id = c.index_id JOIN ( SELECT idx.object_id, nonclusteredname = idx.name, ius.user_seeks FROM sys.indexes idx JOIN sys.dm_db_index_usage_stats ius ON idx.object_id = ius.object_id AND idx.index_id = ius.index_id WHERE idx.type_desc = 'nonclustered' AND ius.user_seeks = ( SELECT MAX(user_seeks) FROM sys.dm_db_index_usage_stats WHERE object_id = ius.object_id AND type_desc = 'nonclustered' ) GROUP BY idx.object_id, idx.name, ius.user_seeks ) nc ON nc.object_id = idx.object_id WHERE idx.type_desc IN ( 'clustered', 'heap' ) AND nc.user_seeks > ( c.user_seeks * 1.50 ) -- 150% AND nc.user_seeks >= ( c.user_lookups * 0.75 ) -- 75% ORDER BY nc.user_seeks DESC |

Identificando índices ausentes (missing index)
Uma das tarefas do dia a dia de um DBA, é identificar índices ausentes no banco de dados, que podem sugerir um ganho de performance de consultas que são frequentemente executadas. Com a query abaixo, podemos tornar essa tarefa um pouco mais fácil, pois consultando as DMV’s de missing index, podemos identificar esses dados rapidamente.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
SELECT mid.statement, migs.avg_total_user_cost * ( migs.avg_user_impact / 100.0 ) * ( migs.user_seeks + migs.user_scans ) AS improvement_measure, OBJECT_NAME(mid.object_id), 'CREATE INDEX [missing_index_' + CONVERT (VARCHAR, mig.index_group_handle) + '_' + CONVERT (VARCHAR, mid.index_handle) + '_' + LEFT(PARSENAME(mid.statement, 1), 32) + ']' + ' ON ' + mid.statement + ' (' + ISNULL(mid.equality_columns, '') + CASE WHEN mid.equality_columns IS NOT NULL AND mid.inequality_columns IS NOT NULL THEN ',' ELSE '' END + ISNULL(mid.inequality_columns, '') + ')' + ISNULL(' INCLUDE (' + mid.included_columns + ')', '') AS create_index_statement, migs.*, mid.database_id, mid.[object_id] FROM sys.dm_db_missing_index_groups mig INNER JOIN sys.dm_db_missing_index_group_stats migs ON migs.group_handle = mig.index_group_handle INNER JOIN sys.dm_db_missing_index_details mid ON mig.index_handle = mid.index_handle WHERE migs.avg_total_user_cost * ( migs.avg_user_impact / 100.0 ) * ( migs.user_seeks + migs.user_scans ) > 10 ORDER BY migs.avg_total_user_cost * migs.avg_user_impact * ( migs.user_seeks + migs.user_scans ) DESC |

Analisando o histograma dos índices
Um ponto muito importante a se considerar após o índice ser criado, é analisar o seu histograma. Utilizando esse recurso, é possível identificar o quão granulado são os dados da tabela e o quão seletivo é o nosso índice, de modo que quanto mais seletivo, melhor ele será utilizado.
Um exemplo disso, é criar um índice na Coluna Sexo em uma tabela de clientes e a distribuição dos dados ficar em 50% para cada um dos valores. Nessa situação, o índice não está sendo muito seletivo e o banco terá que fazer muitas leituras para retornar as informações. Para observar a quantidade de registros para cada valor, observe a coluna EQ_ROWS.
Para visualizar o histograma do índice, pode-se utilizar a procedure DBCC:
|
1 2 |
-- DBCC SHOW_STATISTICS(Nome_da_Tabela, Nome_do_Indice) DBCC SHOW_STATISTICS(Logins, SK01) |
No exemplo abaixo, podemos observar um caso de índice bem seletivo, que apresenta uma densidade de 0,4% e possui várias informações distintas. Quando esse índice for utilizado, irá retornar um volume de dados bem pequeno.
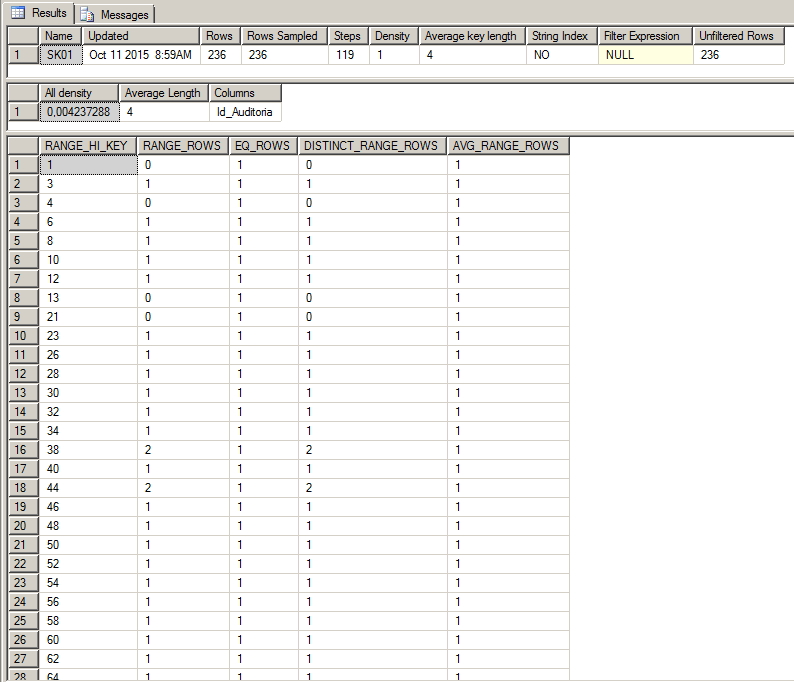
Já no exemplo abaixo, podemos identificar um índice pouco seletivo, com densidade de 50% (apenas 2 valores distintos), sendo que um desses valores (‘DBA’) representa 98% (232 registros de um total de 236) dos dados coletados. Ou seja, caso esse índice seja utilizado e a consulta seja realizada procurando pela palavra ‘DBA’, o índice precisaria retornar 98% dos dados do índice e o otimizador do SQL iria preferir realizar uma operação de Index Scan ao invés do Index Seek.
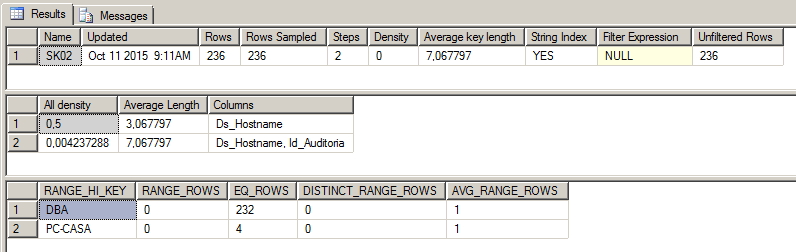
É isso aí pessoal!
Até a próxima!
Parabéns pelo post. Muito bem explicado.
Só explicação espetacular do DR…
Pensa em um blog que está me ajudando à ser promovido kkkk
Obrigado, muito útil.
Obrigado pela explicação e pelo compartilhamento de conhecimento.
Excelente conteúdo, bem didático. Parabéns!
Parabéns,
Foi o conteúdo mais completo e didático que encontrei na net
Dirceu, bom dia.
Parabéns pelo post, muito didático.